정확성 (Accuracy): 데이터가 정확해야 함
1. beer.csv
%matplotlib inline
import pandas as pd
df = pd.read_csv('data/beer.csv', index_col=0)
df.head()df.plot(kind='box', y='abv')
박스플롯을 생성해본 결과
이상점이 3개가 보인다.
'abv'의 Q1(25%) Q3(75%)지점을 구해본다.
describe()
- 수치형 변수들의 통계량을 보여준다.
df['abv'].describe()count 2190.000000
mean 0.060186
std 0.117010
min 0.032000
25% 0.050000
50% 0.055000
75% 0.065000
max 5.500000
Name: abv, dtype: float64
# Q1 = 25%
df['abv'].quantile(0.25)0.05
# Q3 = 75%
df['abv'].quantile(0.75)0.065q1 = df['abv'].quantile(0.25)
q3 = df['abv'].quantile(0.75)
iqr = q3 - q1
25% 지점보다 밑에 있거나,
75% 지점보다 위에 있다면
이상점이다.
condition = (df['abv'] < q1 - 1.5 * iqr) | (df['abv'] > q3 + 1.5 * iqr)df[condition]

위의 박스플롯에서 보였던 이상점 3개가 출력되었다.
2250인덱스의 abv값은 입력실수 이므로 데이터를 수정해준다.
이상값 데이터 수정
df.loc[2250,'abv'] = 0.055df.loc[2250]
abv 0.055
ibu 40.0
id 145
name Silverback Pale Ale
style American Pale Ale (APA)
brewery_id 424
ounces 12.0
Name: 2250, dtype: object
이상점을 다시 출력해보면
condition = (df['abv'] < q1 - 1.5 * iqr) | (df['abv'] > q3 + 1.5 * iqr)
df[condition]
2개로 줄었음을 알 수있다.
남은 2개의 이상점은 맥주가 아닌 것들이 잘못입력된것으로 보인다.
따라서 삭제하도록 한다.
이상점의 인덱스를 출력
df[condition].index
Index([963, 1856], dtype='int64')
이상점 삭제
df.drop(df[condition].index, inplace=True)
df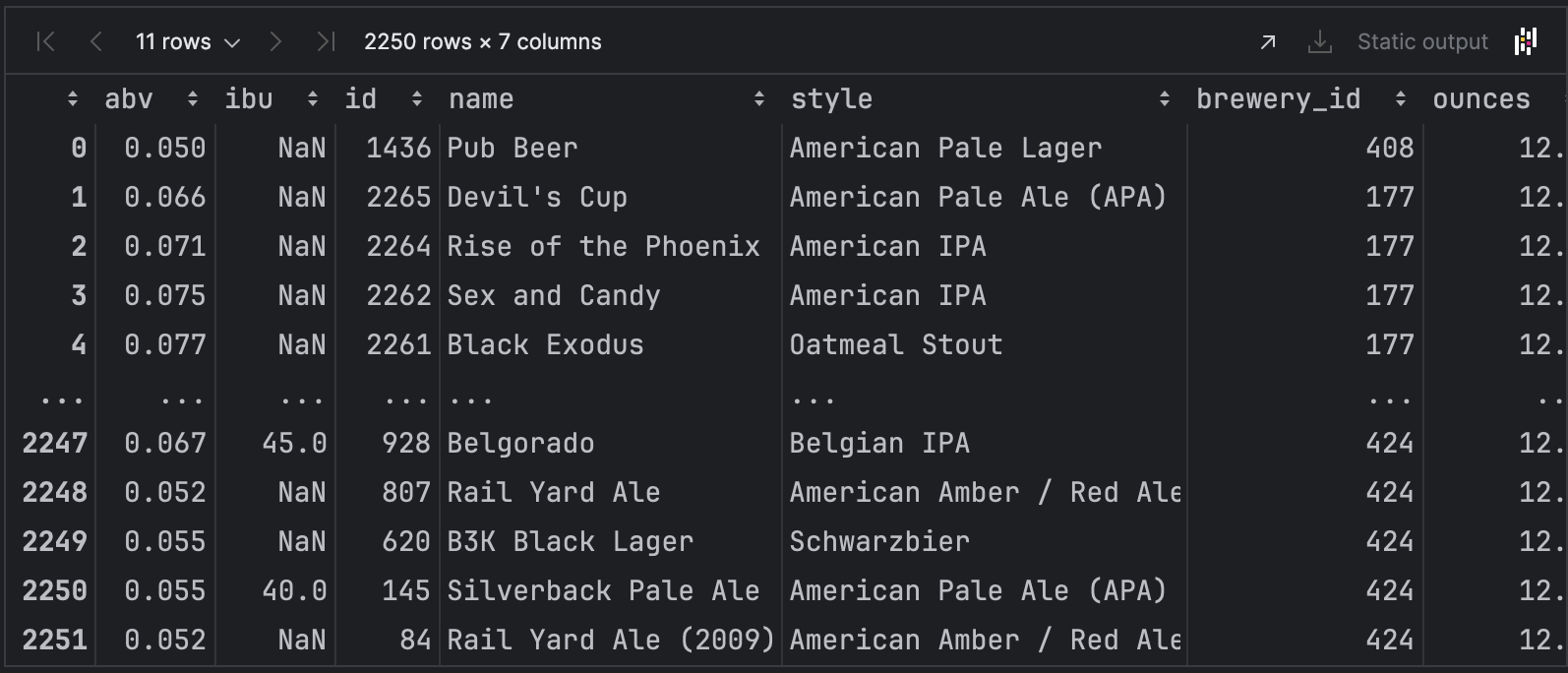
이상점을 다시 확인해본다.
condition = (df['abv'] < q1 - 1.5 * iqr) | (df['abv'] > q3 + 1.5 * iqr)
df[condition]
이상점이 출력되지 않는다.
박스플롯 생성
df.plot(kind='box', y='abv')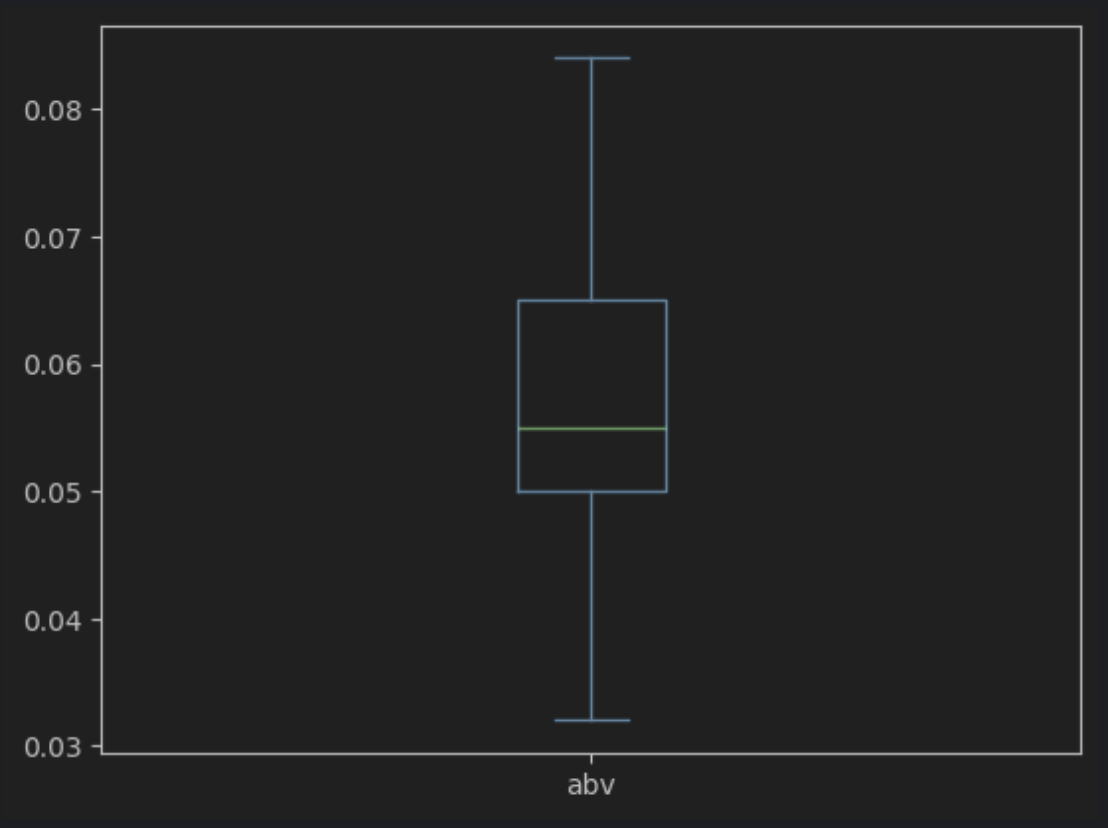
2. exam_outlier.csv
df = pd.read_csv('data/exam_outlier.csv')
df
산점도 출력
df.plot(kind='scatter', x='reading score', y='writing score')
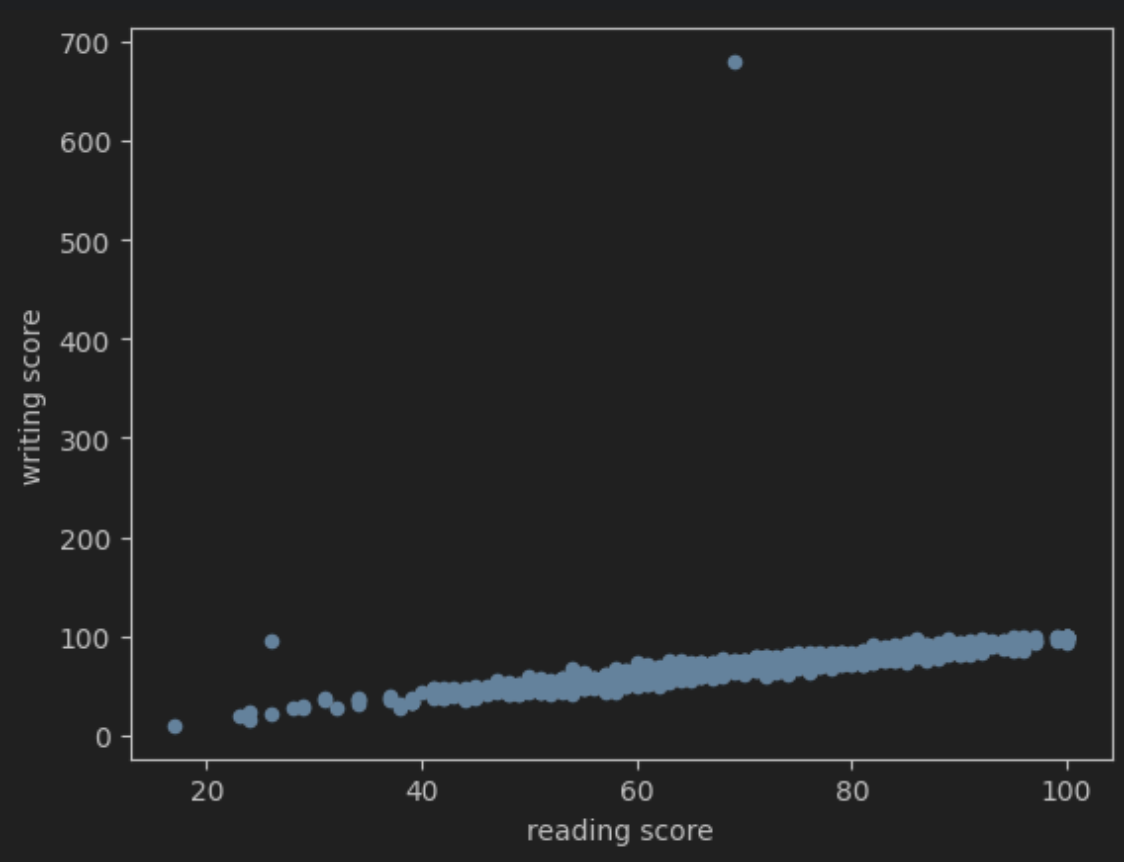
학생들의 읽기 점수와 쓰기 점수가 어떤 연관성이 있는지 확인해보았다.
700에 있는 이상점이 하나있다.
상관계수 출력
df.corr(numeric_only=True)
이상점 찾기
df['writing score'] > 1000 False
1 False
2 False
3 False
4 False
...
995 False
996 False
997 False
998 False
999 False
Name: writing score, Length: 1000, dtype: bool
쓰기 점수를 인덱싱해본다.
df[df['writing score'] > 100]
51번째 인덱스가 이상점이다.
이상점 제거
df.drop(51, inplace=True)df.plot(kind='scatter', x='reading score', y='writing score')
상관계수 출력

읽기와 쓰기의 상관계수가
0.58 -> 0.94로 올라갔다.
하지만 그래프를 보면 하나의 점이 동 떨어져 있는 것을 알 수있다.
# 쓰기는 90이 넘고 앍가눈 40이 안넘는 학생
condition = (df['writing score'] > 90) & (df['reading score'] < 40)
df[condition]
이상점 제거
df.drop(373, inplace=True)
df
df.plot(kind='scatter', x='reading score', y='writing score')

그래프는 오른쪽위로 일직선에 가까움을 볼 수있다.
따라서 양의 상관관계이다.
상관관계를 출력해보면
df.corr(numeric_only=True)
읽기와 쓰기는 0.95로 1에 매우 가까워 강한 양의 상관관계를 알 수있다.
'Data & AI Intelligence > ▶Preprocessing & EDA' 카테고리의 다른 글
| 06.Numpy_matmul (0) | 2025.10.24 |
|---|---|
| 데이터 클리닝(유일성) (0) | 2024.06.04 |
| 데이터 클리닝(완결성) (0) | 2024.06.04 |
| 데이터 정제 (0) | 2024.06.04 |
| Pandas 기초: 데이터 타입 확인 및 외부 CSV 데이터 로드 (0) | 2024.06.03 |

