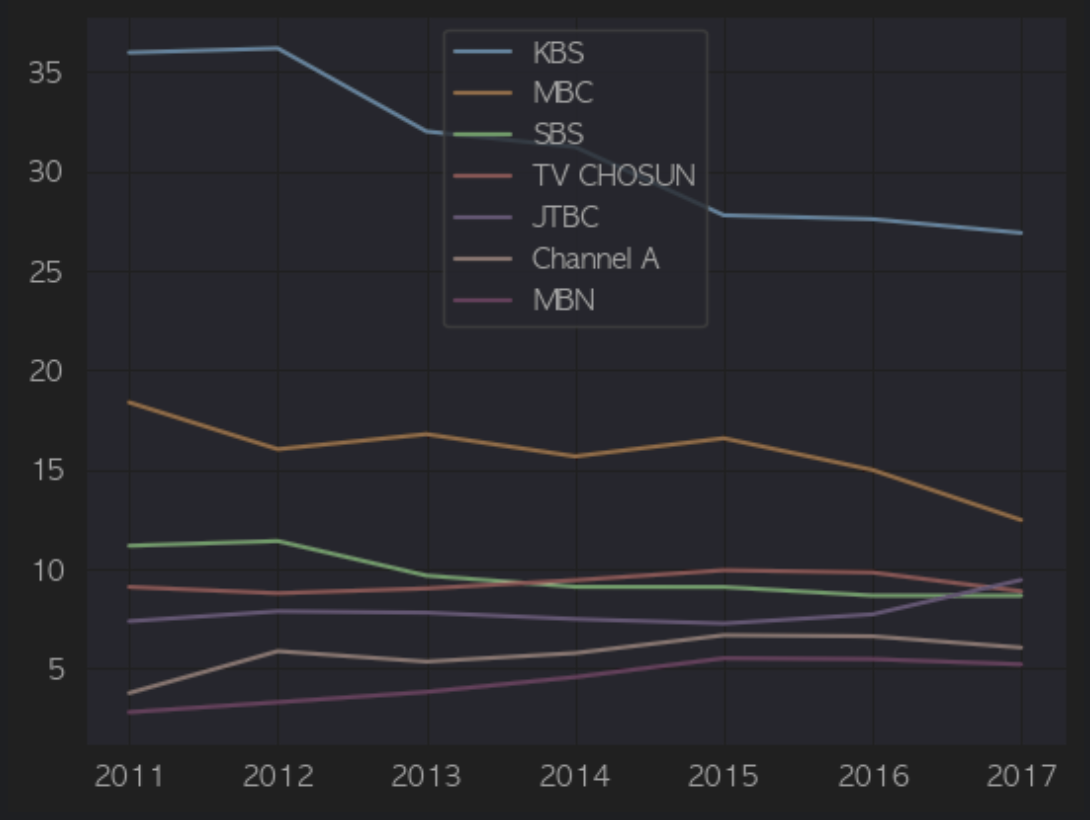
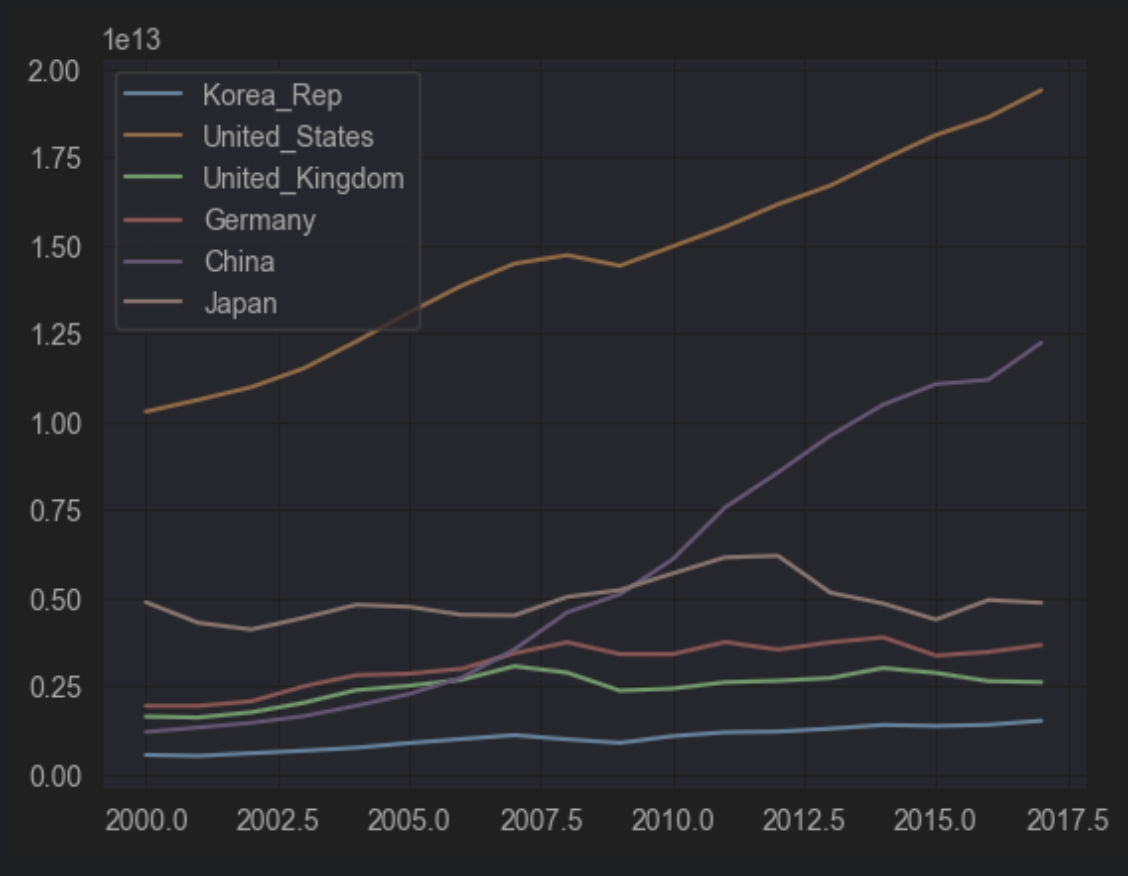
1. [선 그래프 실습 문제] 국가별 경제 성장
실습 설명
한국(Korea_Rep), 미국(United_States), 영국(United_Kingdom), 독일(Germany), 중국(China), 일본(Japan)의 GDP 그래프를 그려 보세요.
%matplotlib inline
import pandas as pd
df = pd.read_csv('data/gdp.csv', index_col=0)
df.plot(y=['Korea_Rep', 'United_States','United_Kingdom','Germany','China','Japan'])
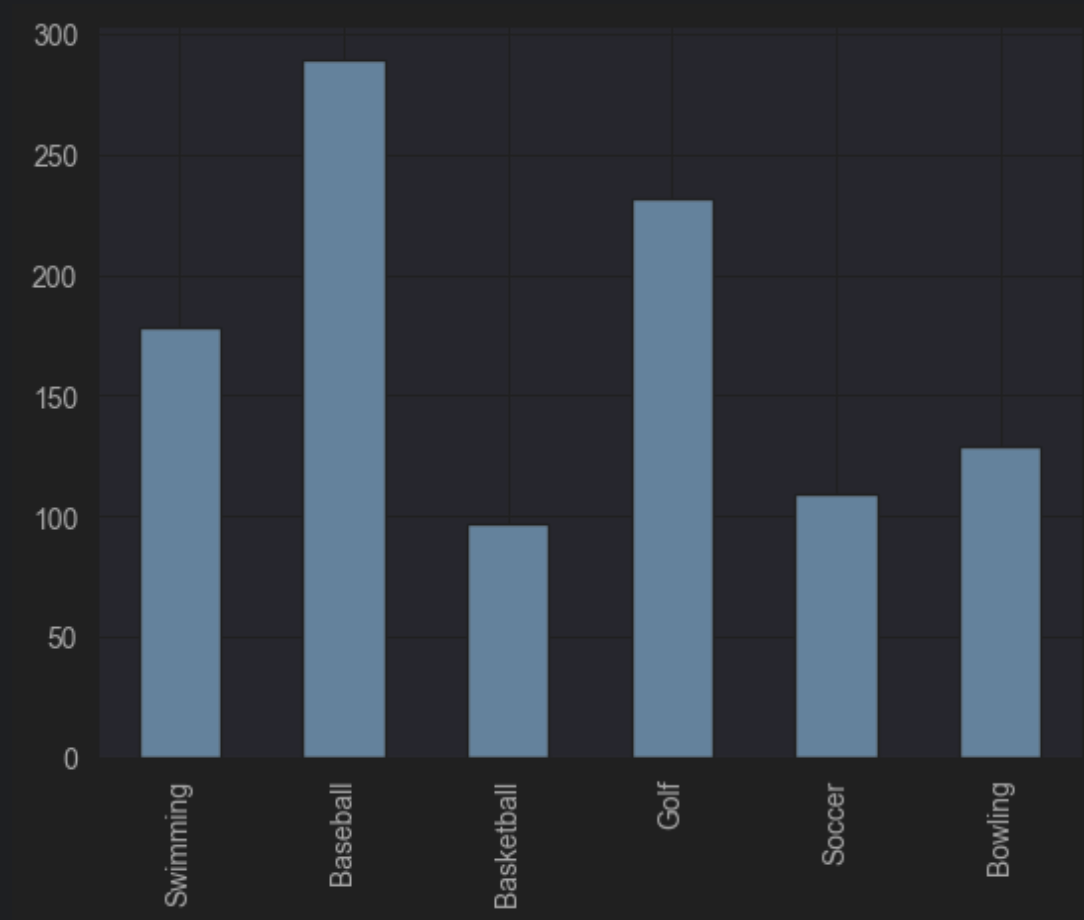
2. [막대 그래프 실습 문제] 실리콘 밸리에는 누가 일할까?1
실습 설명
실리콘 밸리에서 일하는 사람들의 정보가 있습니다.
직업, 종류, 인종, 성별 등이 포함되어 있는데요.
실리콘 밸리에서 일하는 남자 관리자(Managers)에 대한 인종 분포를 막대그래프로 다음과 같이 그려보세요.
%matplotlib inline
import pandas as pd
df = pd.read_csv('data/silicon_valley_summary.csv')
df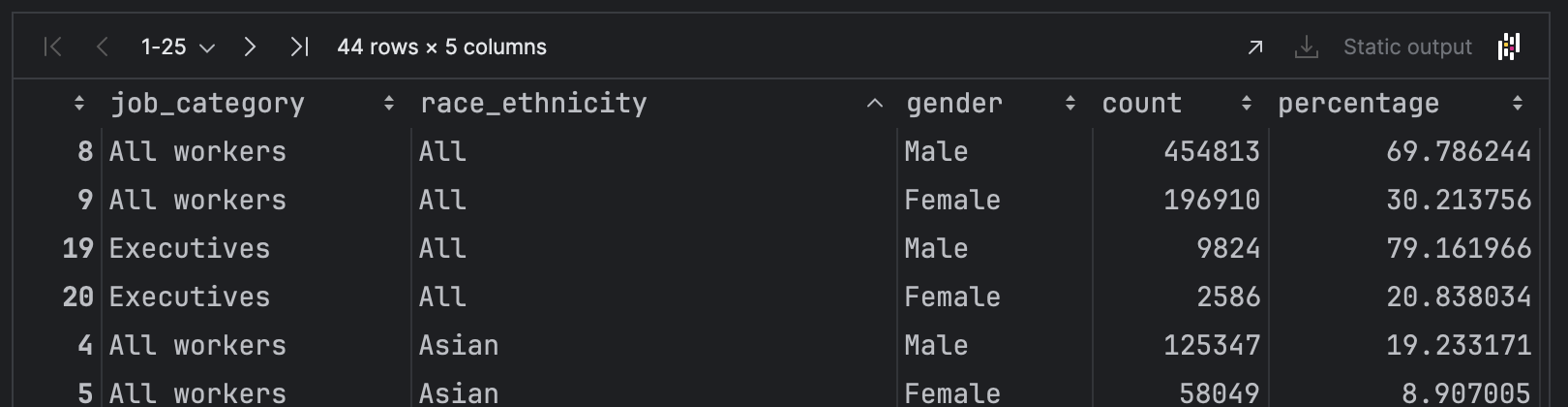
데이터 프레임을 출력해보면 인종(race_ethnicity)에 인덱스에 All이 포함되어 있다.
인종에 대한 그래프를 그려야 하므로 All을 제외 시켜야한다.
우리가 출력해야 하는 내용
1. 성별(gender) : 남자 (Male)
2. 직업(job_category) : 관리자 (Managers)
3. 인종(race_ethnicity) : 모든 인종
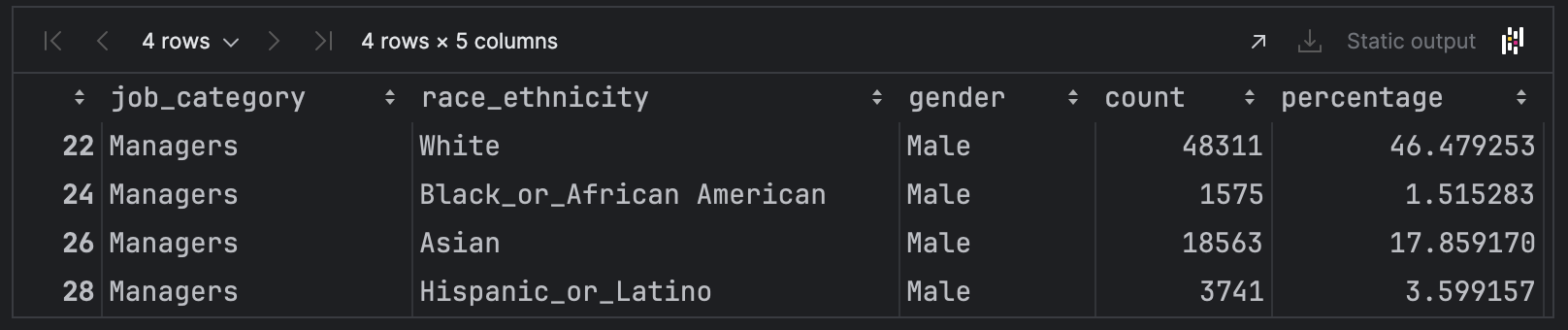
gender = df['gender'] == 'Male'
job_category = df['job_category'] == 'Managers'
race_ethnicity = df['race_ethnicity'] != 'All'df[gender & race_ethnicity & job_category]조건에 맞는 df 출력
막대그래프 생성
df[gender & race_ethnicity & job_category].plot(kind='bar', x='race_ethnicity', y='count')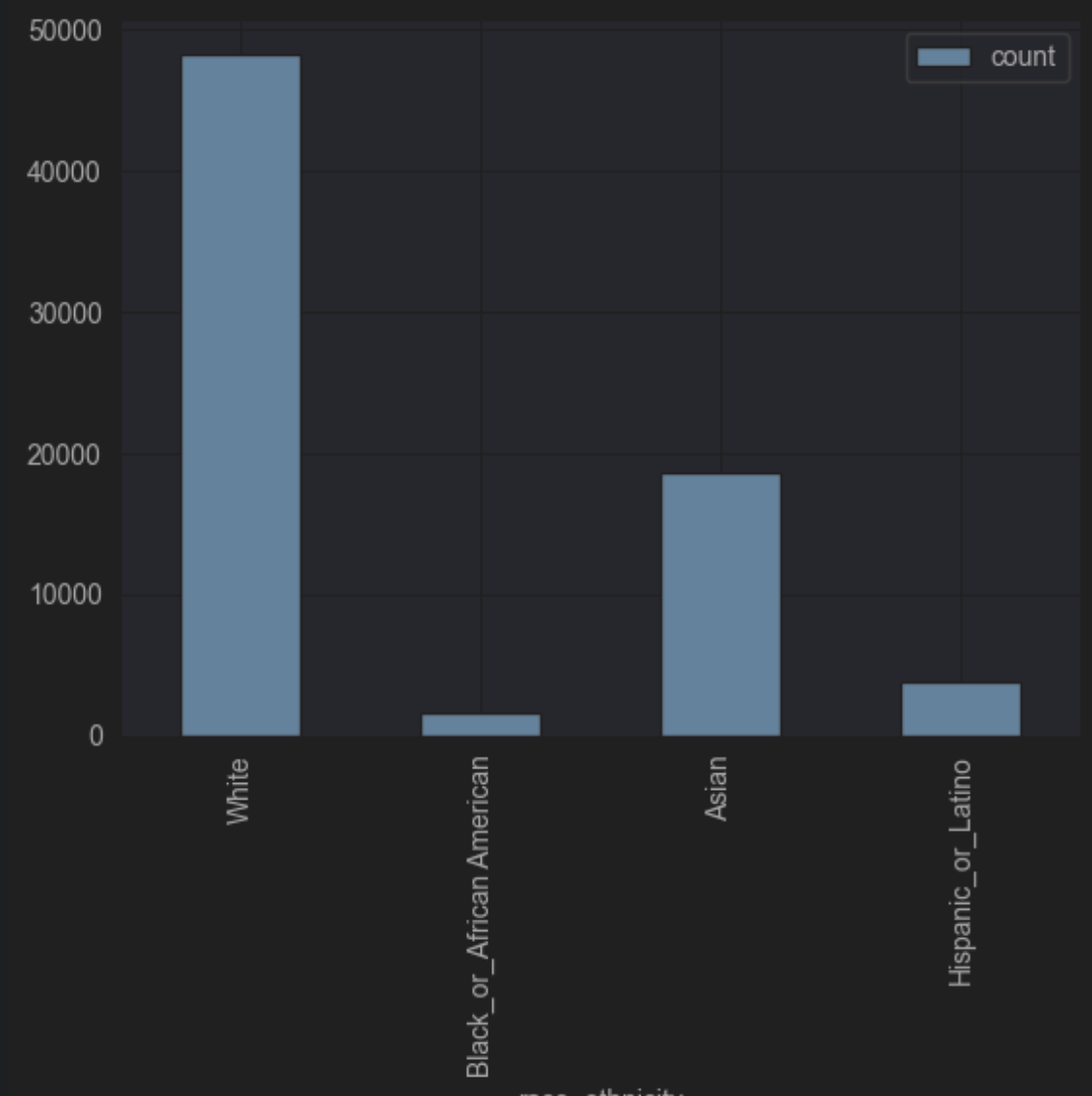
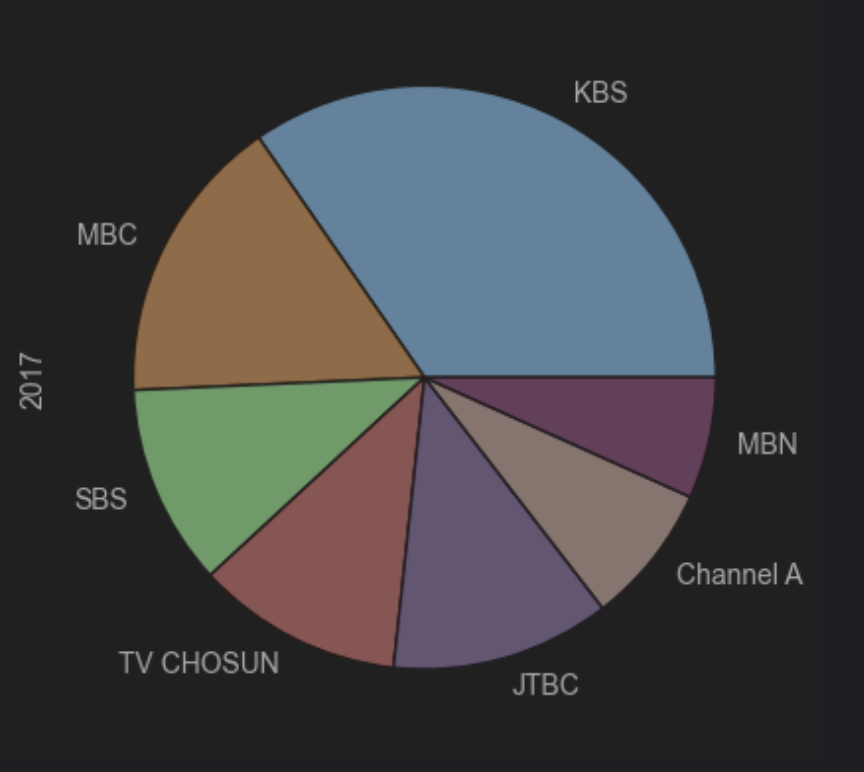
3. [파이 그래프 실습 문제] 실리콘 밸리에는 누가 일할까?2
실습 설명
이번에는 어도비 (Adobe)의 직원 분포를 한번 살펴봅시다.
어도비 전체 직원들의 직군 분포를 파이 그래프로 그려보세요.
(인원이 0인 직군은 그래프에 표시되지 않아야 합니다.)
%matplotlib inline
import pandas as pd
df = pd.read_csv('data/silicon_valley_details.csv')
df
우리가 출력해야 하는 내용
1. 회사(company) : Adove
2. 인종(race) : Overall_totals
3. 인원(count)이 0인 직군 제외 : count가 0이면 제외
그리고 job_category에 있는 직군이 아닌 Totals와 job_category도 제외시켜준다.
boolean_adobe = df['company'] == 'Adobe'
boolean_all_races = df['race'] == 'Overall_totals'
boolean_count = df['count'] != 0
boolean_job_category = (df['job_category'] != 'Totals') & (df['job_category'] != 'Previous_totals')
조건에 맞게 df를 생성
df_adobe = df[boolean_adobe & boolean_all_races & boolean_count & boolean_job_category]
df_adobe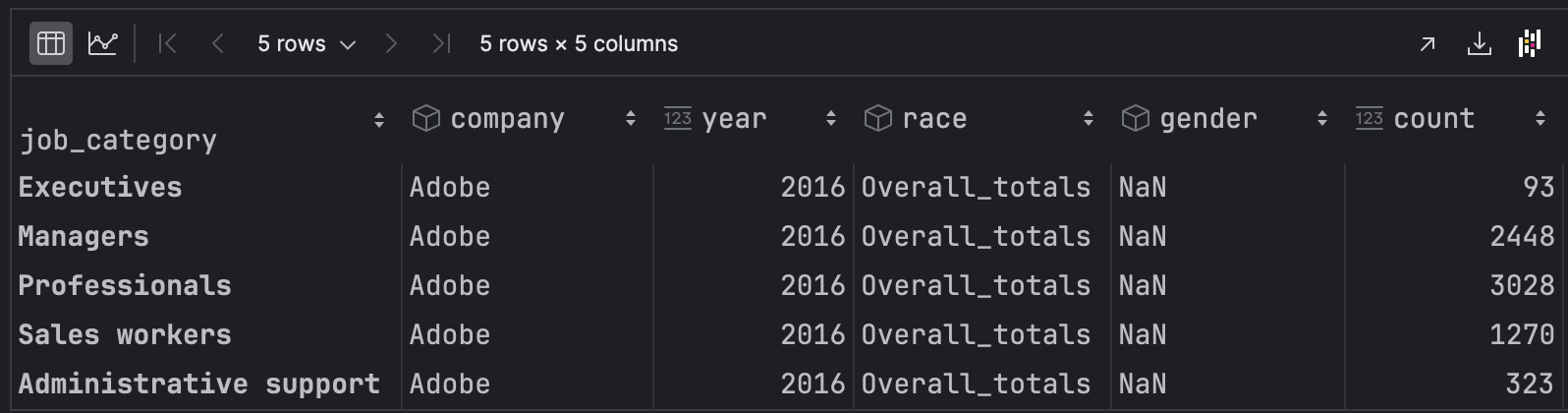
파이그래프 생성
df_adobe.plot(kind='pie', y='count')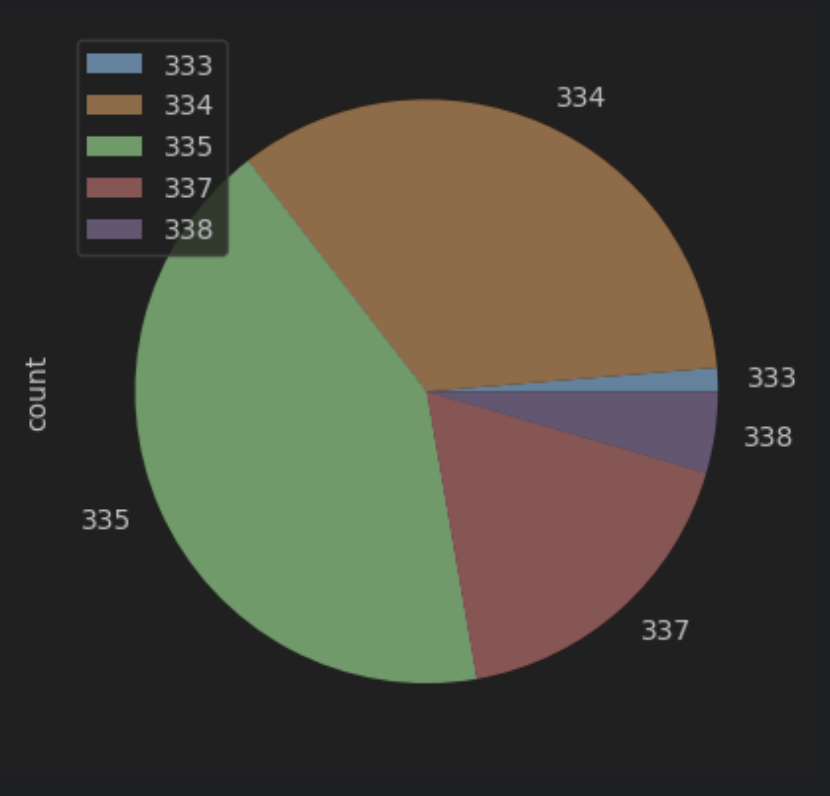
파이그래프는 인덱스를 기준으로 범례를 생성한다.
따라서 우리가 원하는 직군들의 분포를 범례로 지정하려면
job_category가 인덱스로 바뀌어야한다.
set_index : 열을 인덱스로 지정
df_adobe.set_index('job_category', inplace=True)
df_adobejob_category를 인덱스로 지정
df_adobe.plot(kind='pie', y= 'count')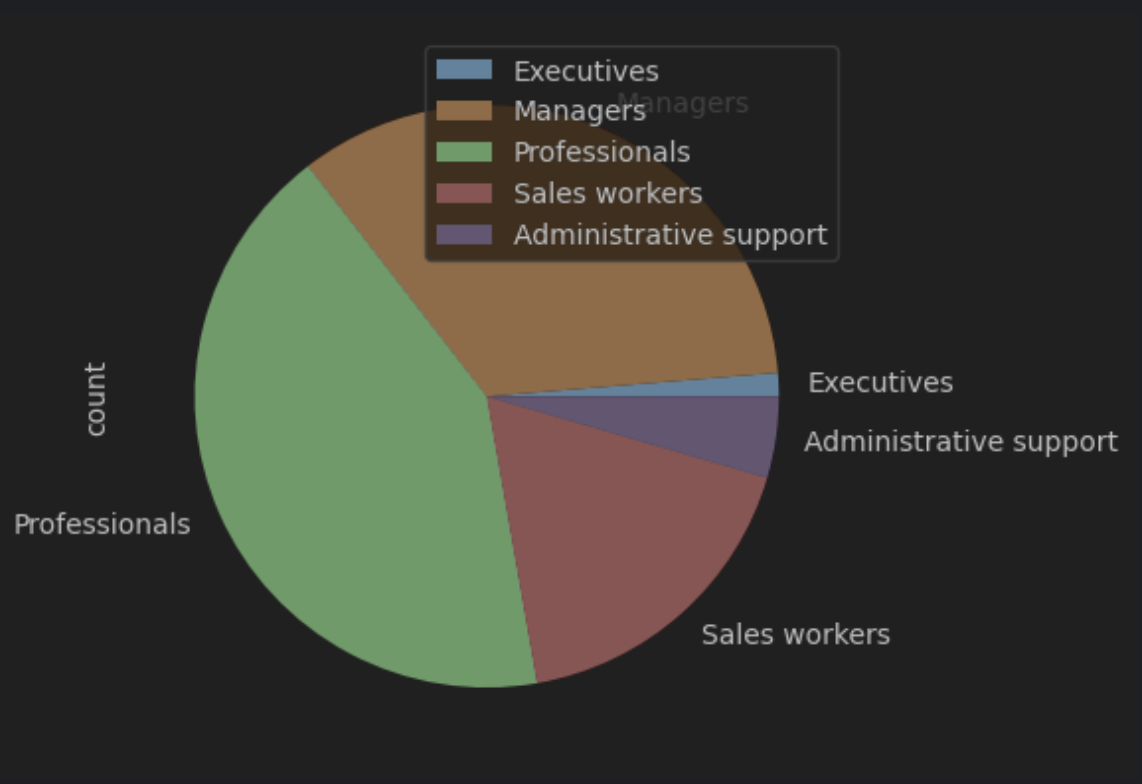
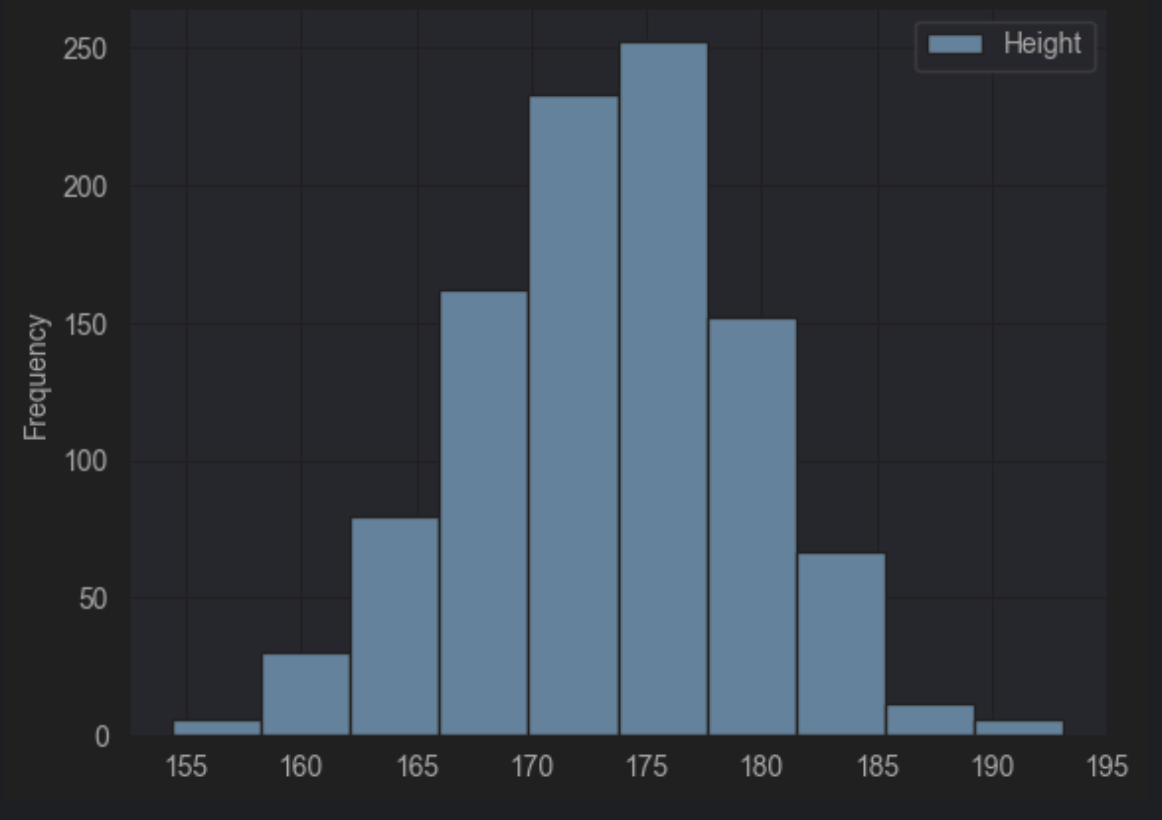
4. [히스토그램 실습 문제] 스타벅스 음료의 칼로리는?1
실습 설명
스타벅스 음료의 칼로리 및 영양소 정보가 있습니다.
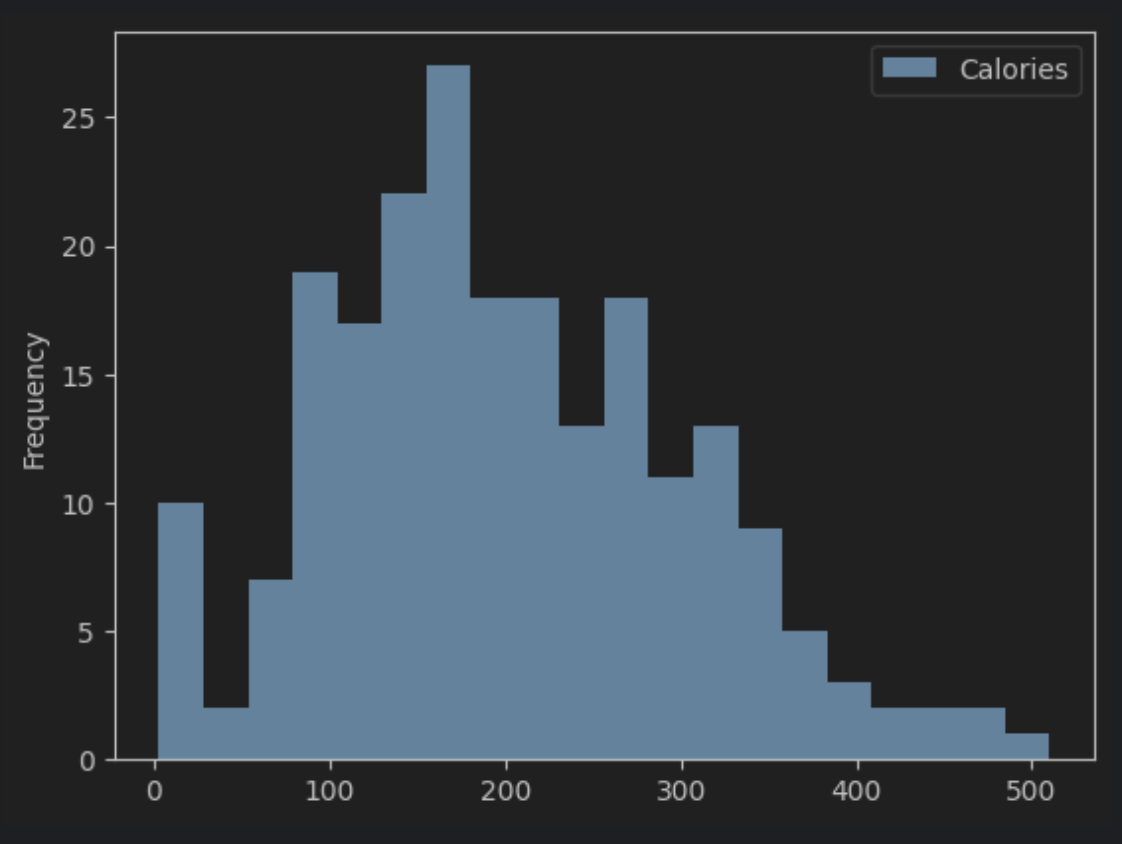
스타벅스 음료의 칼로리 분포는 어떻게 되는지, 히스토그램을 그려서 확인해 봅시다.
원하는 결과가 나오도록 df.plot() 메소드의 괄호를 채워 보세요!
칼로리의 구간은 총 20개로 나누어 주세요.
%matplotlib inline
import pandas as pd
df = pd.read_csv('data/starbucks_drinks.csv')
df.plot()
df.plot(kind = 'hist', y='Calories', bins = 20)
5. [박스플롯 실습 문제] 스타벅스 음료의 칼로리는?2
실습 설명
이번엔 스타벅스 음료의 칼로리를 박스 플롯으로 그려봅시다.
%matplotlib inline
import pandas as pd
df = pd.read_csv('data/starbucks_drinks.csv')
df.plot(kind='box',y='Calories')
박스수염 바깥으로 칼로리 500이 넘는 이상점이 하나 보입니다.
카페음료와 칼로리를 칼로리가 높은 순으로 출력해보겠습니다.
df.loc[:,['Beverage','Beverage_prep','Calories']].sort_values(by='Calories', ascending=False)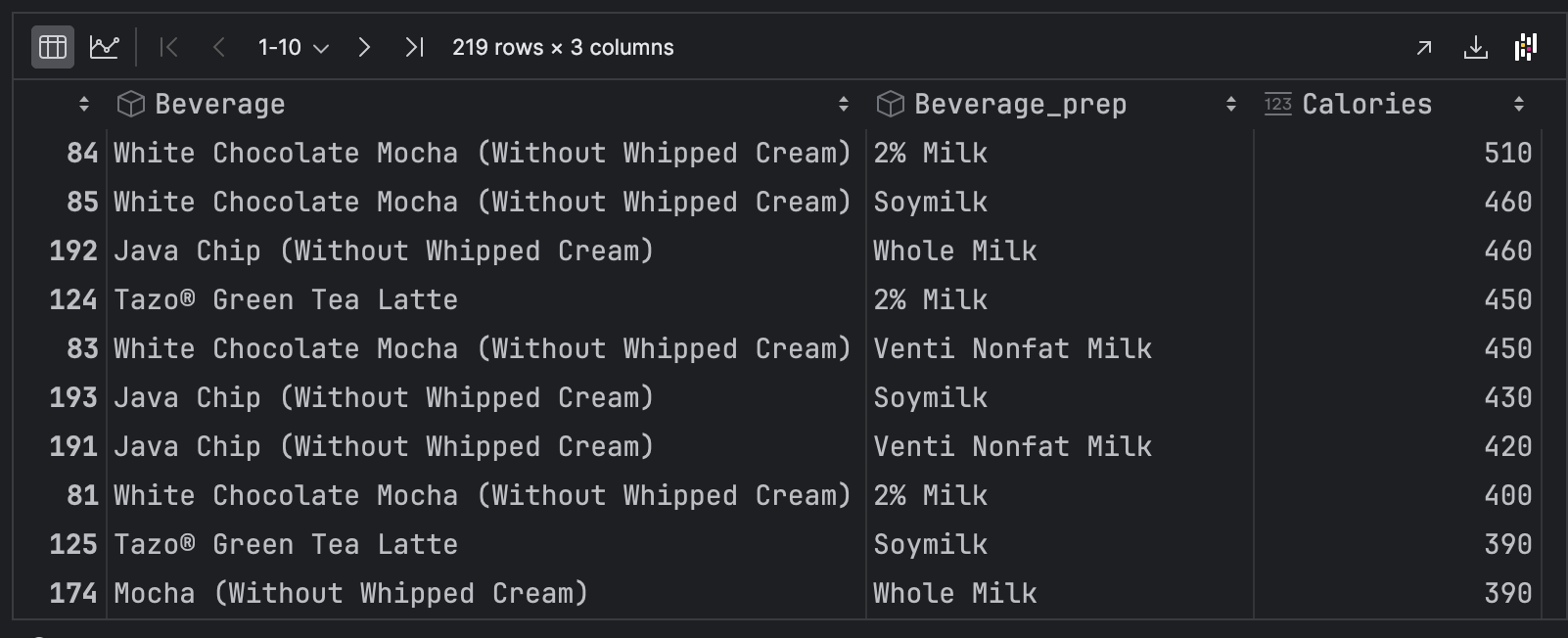
화이트초콜릿 모카가 510칼로리 음료였습니다.
'데이터 분석 > Data_visualization' 카테고리의 다른 글
| 데이터 시각화방법 (0) | 2024.06.03 |
|---|---|
| 1. 시각화와 그래프 (0) | 2024.06.03 |