유일성 (Uniqueness): 동일한 데이터가 불필요하게 중복되어 있으면 안됨
import pandas as pd
df = pd.read_csv('data/dust.csv', index_col=0)
df.head()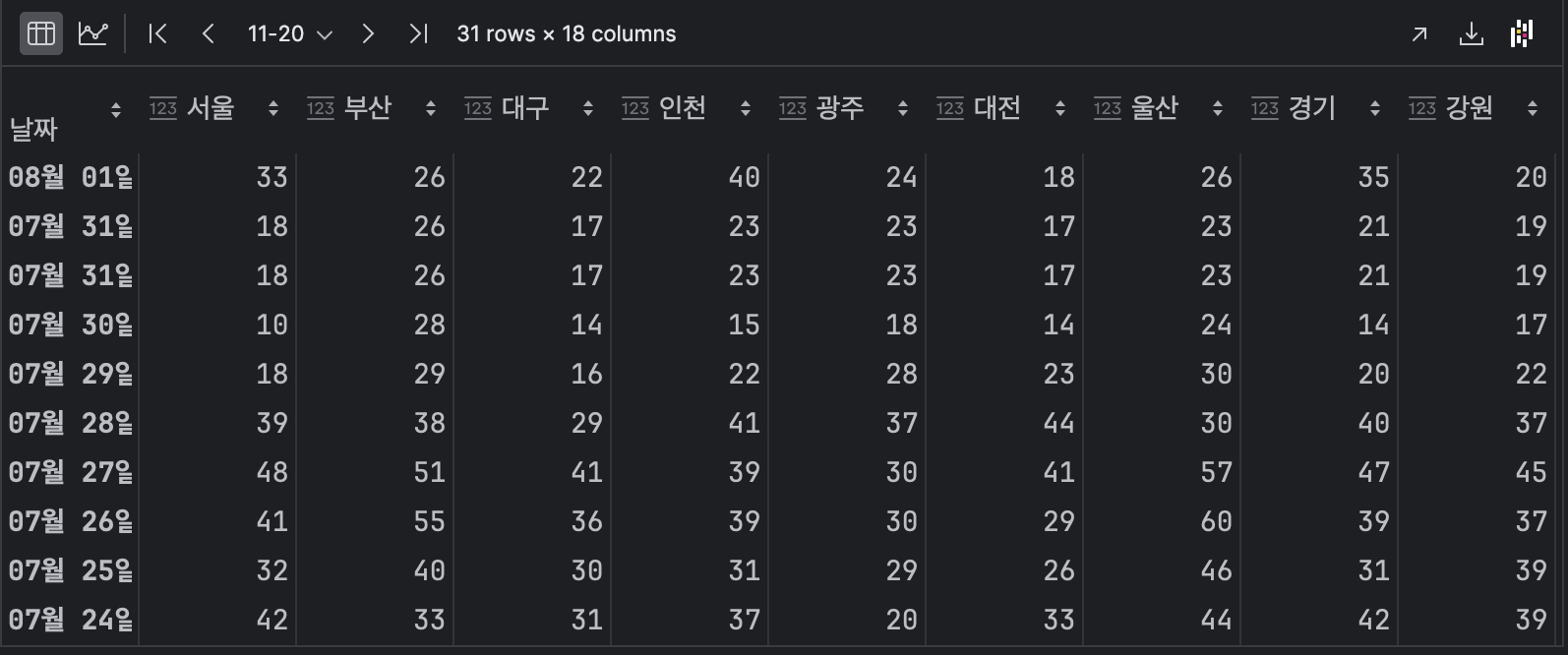
중복되는 row가 존재한다.
날짜를 출력해서 정확하게 확인을 다시한다.
날짜는 index이므로 index로 출력한다.
df.indexIndex(['08월 11일', '08월 10일', '08월 09일', '08월 08일', '08월 07일', '08월 06일',
'08월 05일', '08월 04일', '08월 03일', '08월 02일', '08월 01일', '07월 31일',
'07월 31일', '07월 30일', '07월 29일', '07월 28일', '07월 27일', '07월 26일',
'07월 25일', '07월 24일', '07월 23일', '07월 22일', '07월 21일', '07월 20일',
'07월 19일', '07월 18일', '07월 17일', '07월 16일', '07월 15일', '07월 14일',
'07월 13일'],
dtype='object', name='날짜')
인덱스의 개수를 출력
df.index.value_counts()날짜
07월 31일 2
08월 11일 1
07월 26일 1
07월 14일 1
07월 15일 1
07월 16일 1
07월 17일 1
07월 18일 1
07월 19일 1
07월 20일 1
07월 21일 1
07월 22일 1
07월 23일 1
07월 24일 1
07월 25일 1
07월 27일 1
08월 10일 1
07월 28일 1
07월 29일 1
07월 30일 1
08월 01일 1
08월 02일 1
08월 03일 1
08월 04일 1
08월 05일 1
08월 06일 1
08월 07일 1
08월 08일 1
08월 09일 1
07월 13일 1
Name: count, dtype: int64
인덱스의 개수를 출력해보니
7월 31일의 row만 2개임을 알 수있다.
7월 31일의 값들을 출력해본다.
df.loc['07월 31일']
모든 컬럼의 값이 일치한다.
중복되는 row삭제
df.drop_duplicates()
- 중복된 row를 삭제한다.
기존 데이터에 중복row 없앤 데이터프레임을 덮어씌우려면 inplace=True 작성
df.drop_duplicates()df.drop_duplicates(inplace=True)
df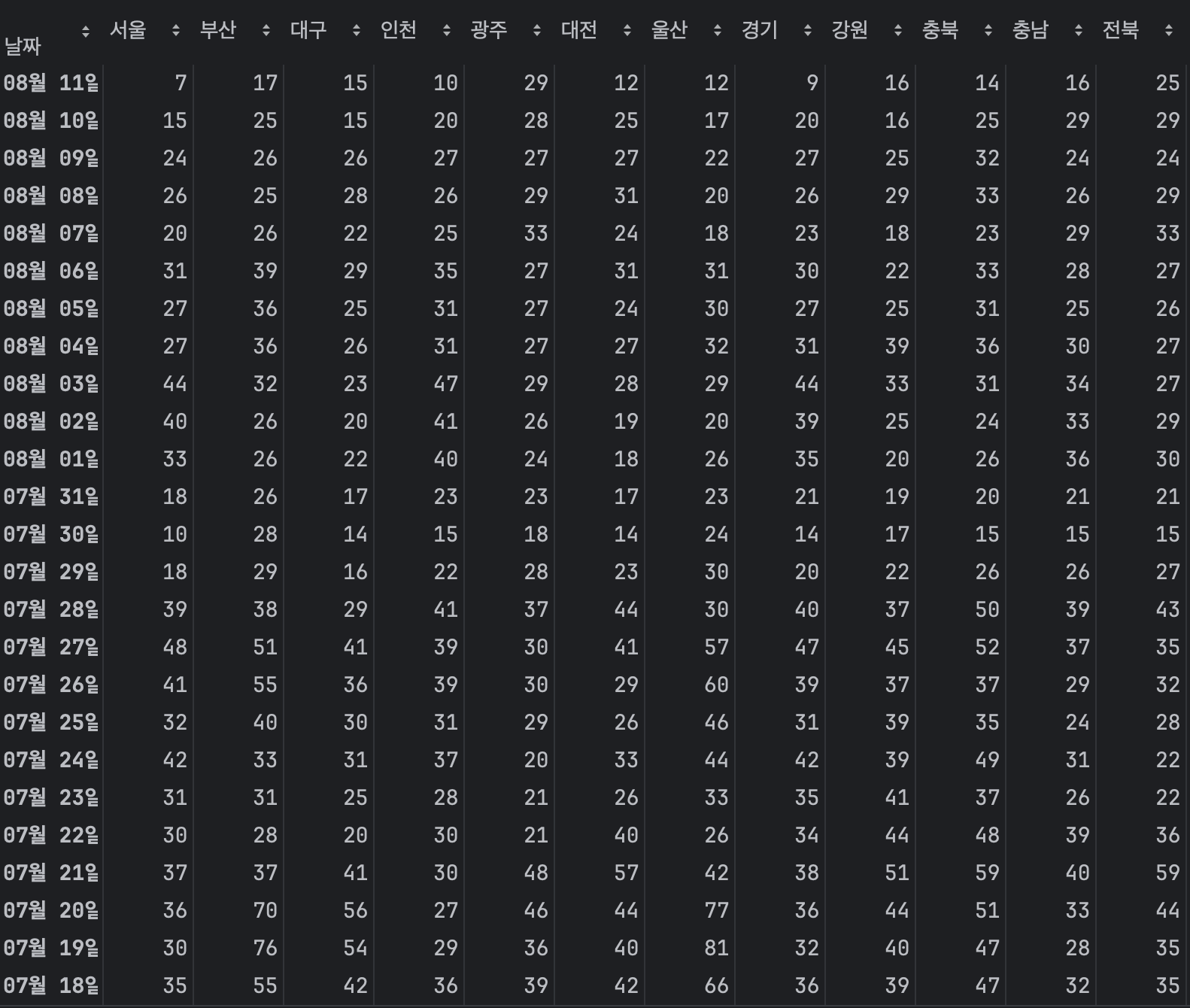
중복된 row가 삭제되었다.
중복되는 columns찾기
만약 두 컬럼이 완전한 동일한 데이터를 갖고있다면 하나는 삭제해도 된다.
row와 컬럼 위치 변경
df.T
df.T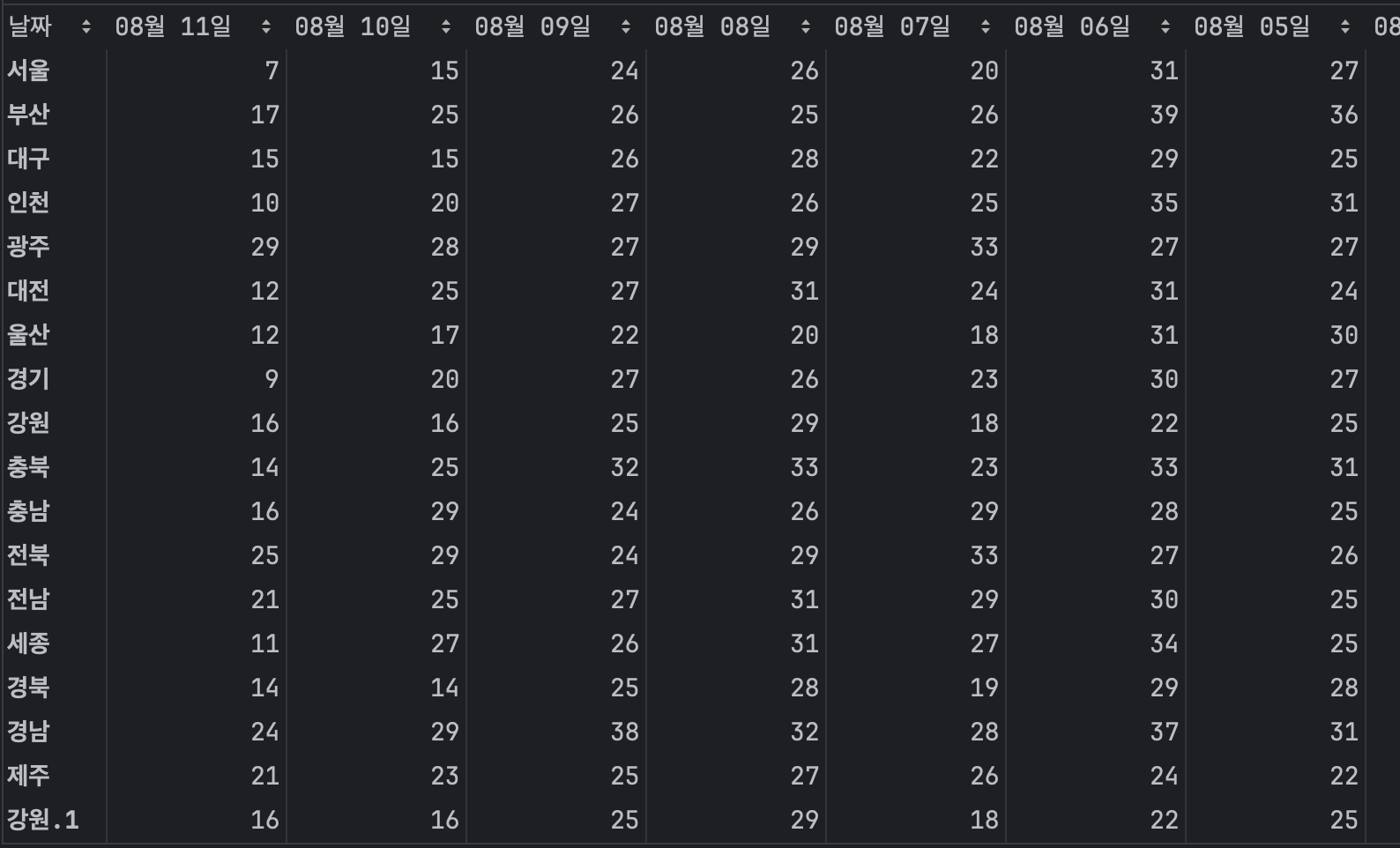
'강원'과 '강원.1'의 데이터 값이 동일하다.
df.T.drop_duplicates()

'강원'과 '강원.1'의 데이터 값이 동일하여 삭제되었다.
그리고 데이터를 다시 로우와 컬럼 위치를 변경시켜준다.
df = df.T.drop_duplicates().T
df
'Data & AI Intelligence > ▶Preprocessing & EDA' 카테고리의 다른 글
| 06.Numpy_matmul (0) | 2025.10.24 |
|---|---|
| 데이터 클리닝(정확성) (0) | 2024.06.04 |
| 데이터 클리닝(완결성) (0) | 2024.06.04 |
| 데이터 정제 (0) | 2024.06.04 |
| Pandas 기초: 데이터 타입 확인 및 외부 CSV 데이터 로드 (0) | 2024.06.03 |

