[코드잇] 데이터클리닝 attendance.csv
완결성 (Completeness): 필수적인 데이터는 모두 기록되어 있어야함, 결측값이 처리
df = pd.read_csv('data/attendance.csv', index_col=0)
df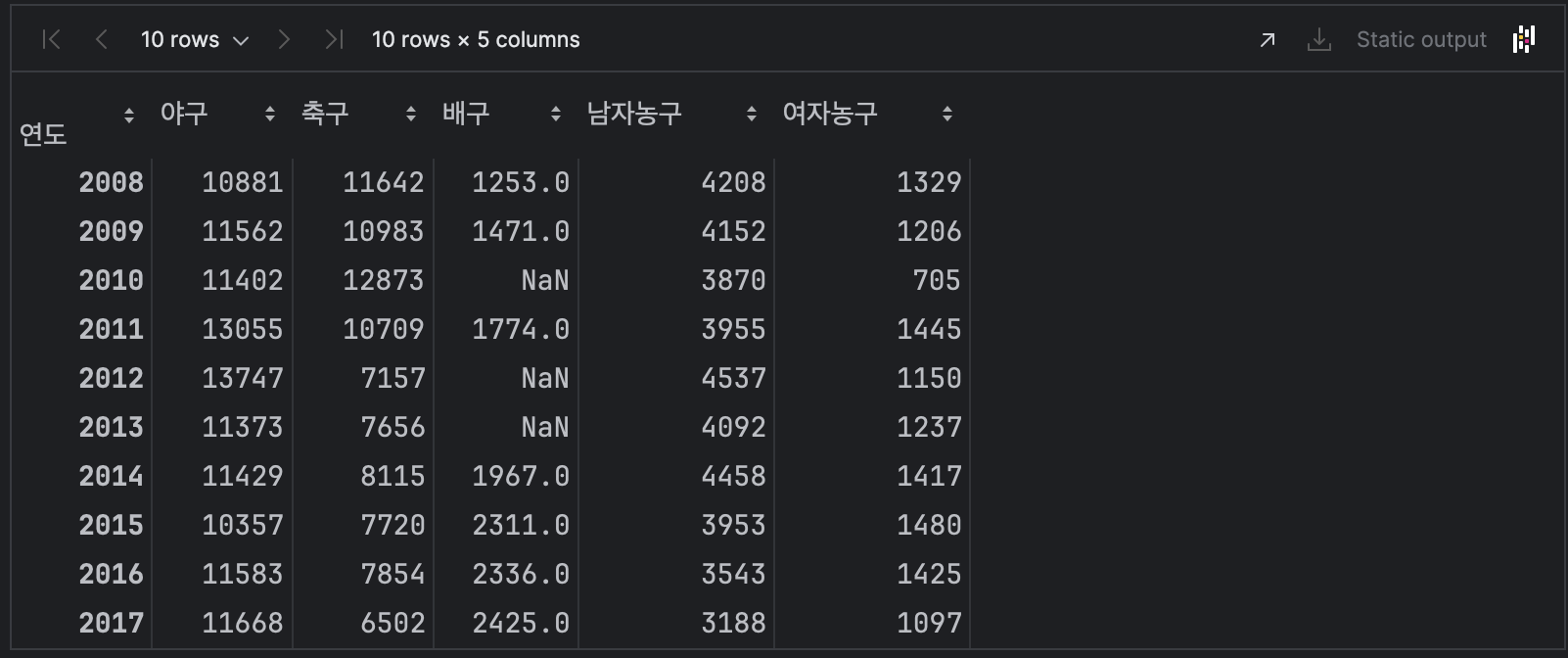
isnull() : 결측값을 True로 반환
결측값이 있는 위치 찾기
결측값이 있는 위치만 True반환
df.isnull()
결측값의 개수 세기
df.isnull().sum()
배구 컬럼에만 결측값이 3개가 있음을 알 수 있다.
결측값 해결방법
1. 그대로 두기
2. 결측값 레코드 지우기 dropna()
결측값 레코드 지우기
df.dropna()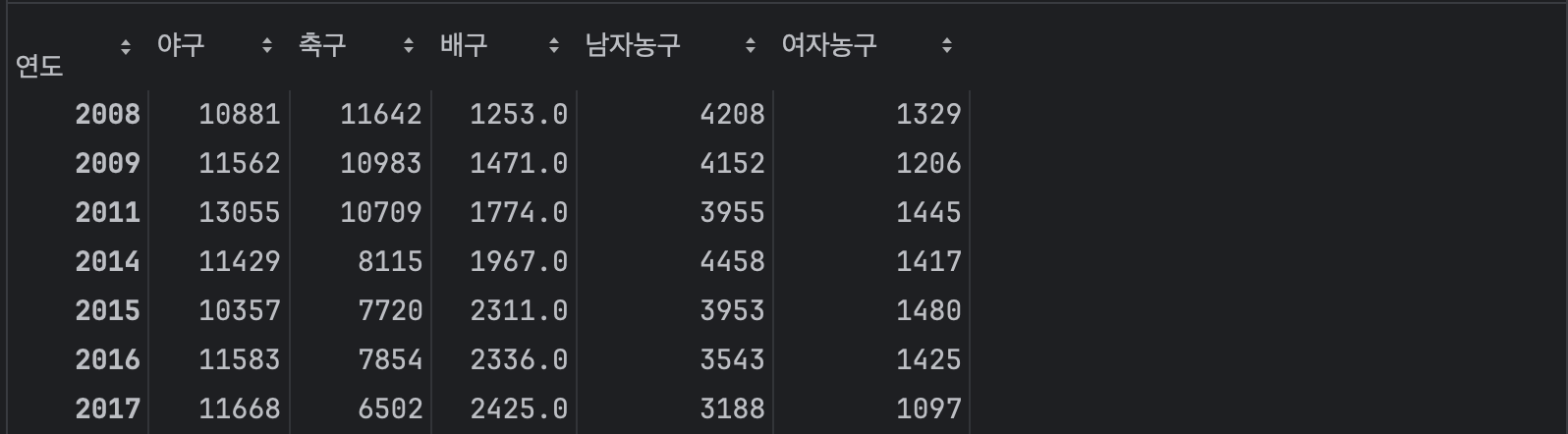
배구에 결측값이 사라졌다.
결측값을 없앤 데이터프레임을 기존의 데이터에 덮어씌우려면 inplace=True를 작성해줘야 한다.
df.dropna(inplace=True)
df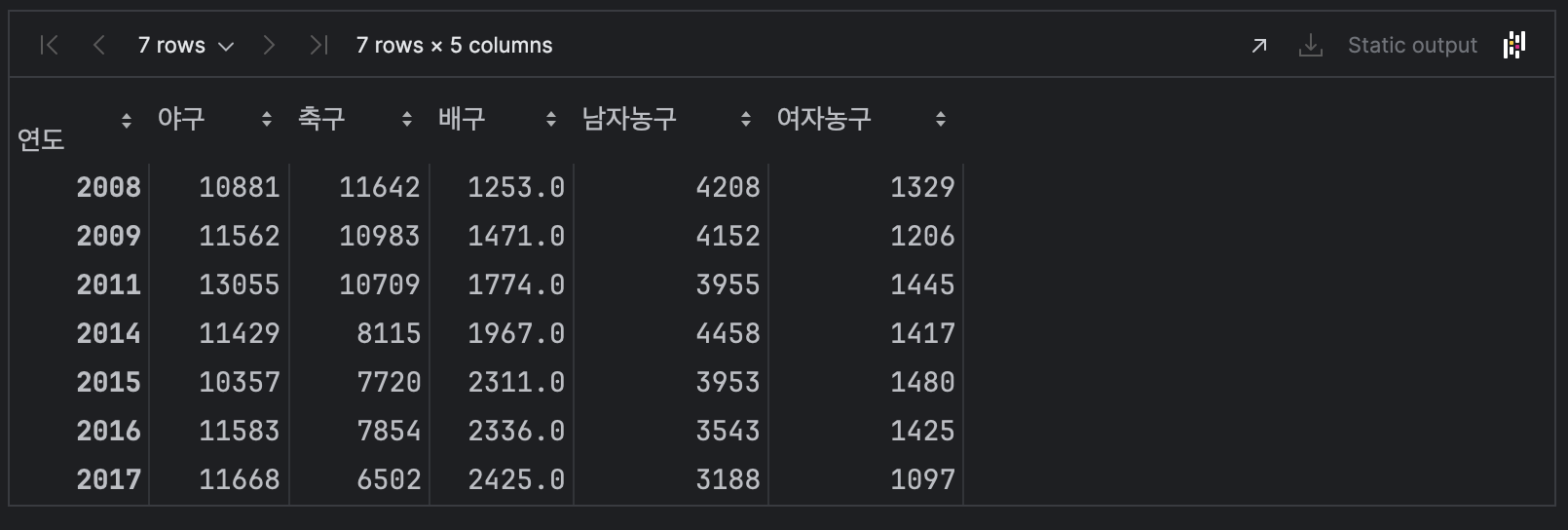
기존데이터에서 2010, 2012, 2013년 데이터가 완전히 사라졌음을 알 수있다.
결측값이 많은 컬럼의 데이터만 포기하기
df = pd.read_csv('data/attendance.csv', index_col=0)
df
결측값이 있는 배구컬럼을 삭제한다.
기본값은 axis=0 이다.
axis=0(index)
- 행 방향 기준
axis=1(columns)
-열 방향 기준
둘 다 같은 결과 출력
df.dropna(axis=1)df.dropna(axis='columns')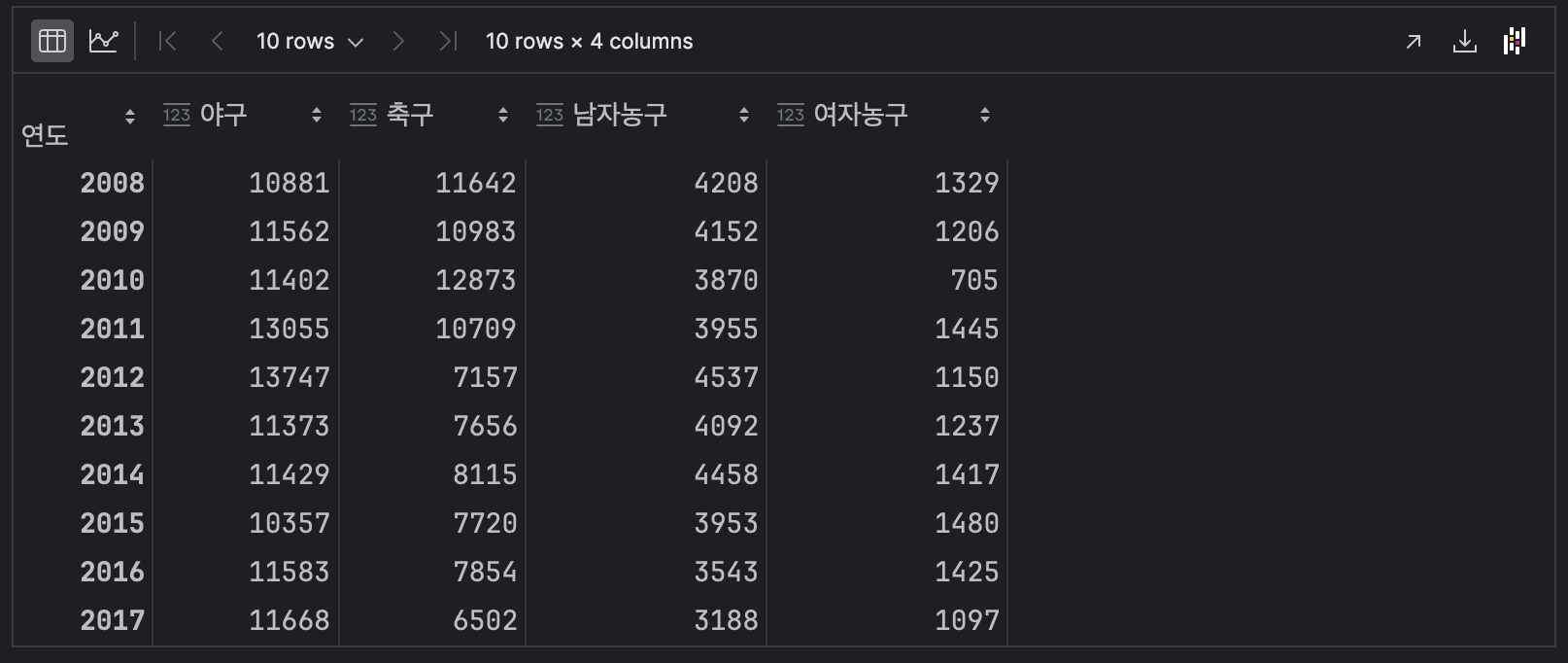
배구 컬럼이 제거되었다.
현재 가진 데이터를 보존하기 : 결측값 대체하기
1. df.fillna(0) : 0으로 채우기
2. df.fillna(df.mean()) : 평균으로 채우기
3. df.fillna(df.median()) : 중앙값으로 채우기
★기존 데이터를 변경하려면 inplace=True
결측값을 0으로 채우기
df.fillna(0)
결측값을 평균으로 채우기
df.fillna(df.mean())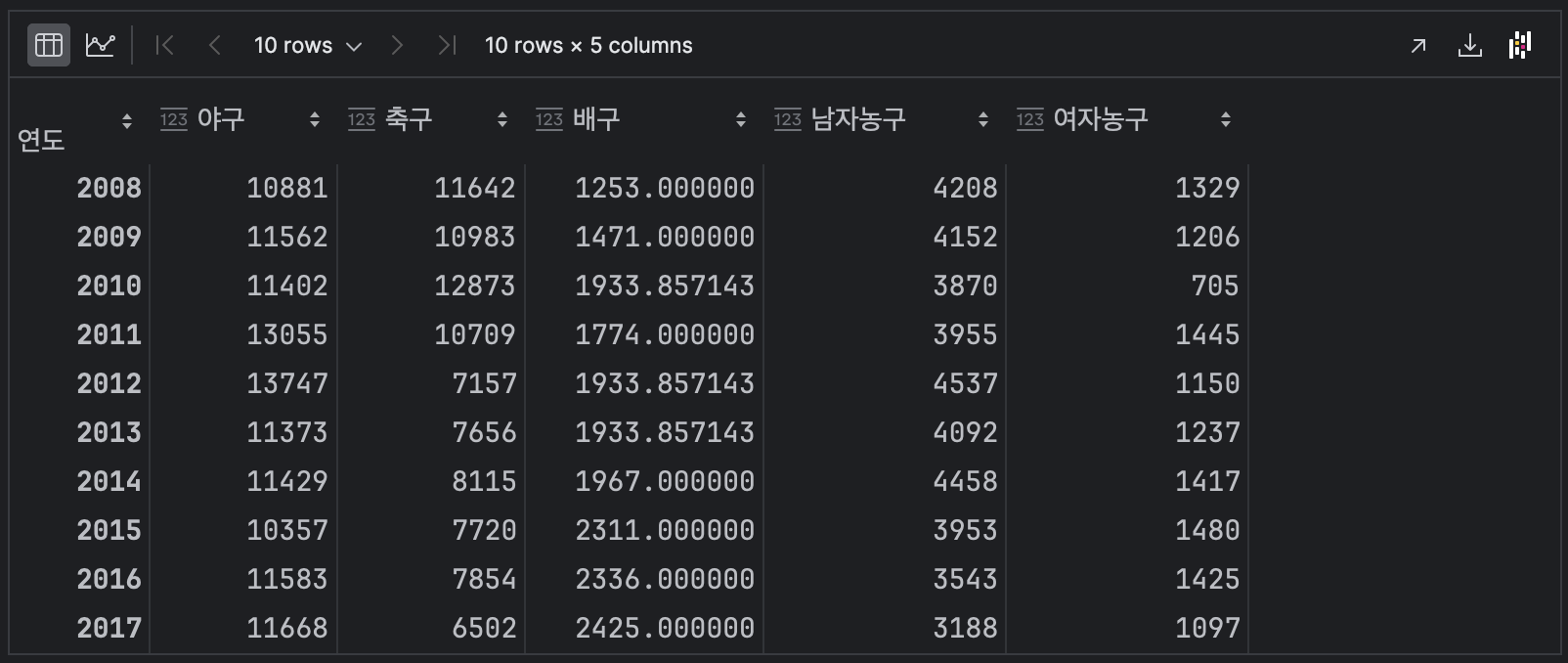
결측값을 중앙값으로 채우기
df.fillna(df.median())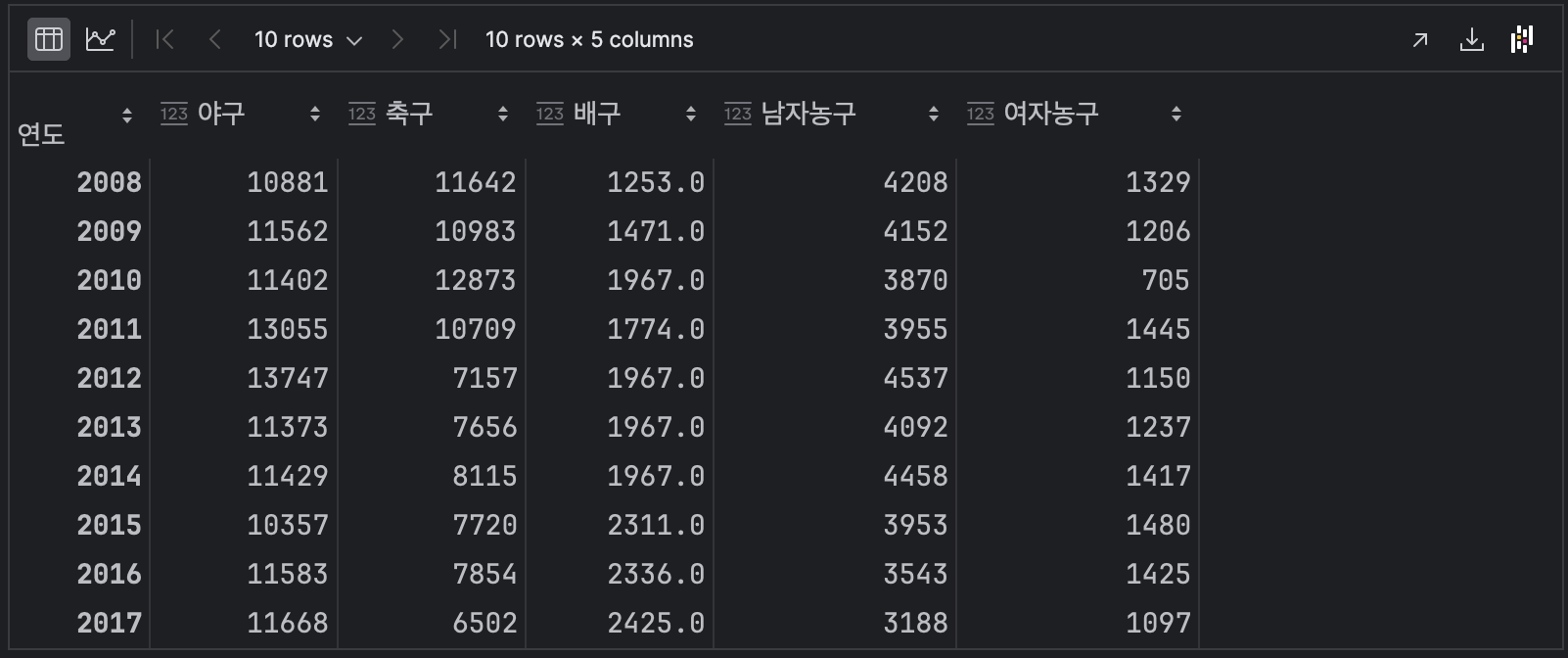
'Data & AI Intelligence > ▶Preprocessing & EDA' 카테고리의 다른 글
| 데이터 클리닝(정확성) (0) | 2024.06.04 |
|---|---|
| 데이터 클리닝(유일성) (0) | 2024.06.04 |
| 데이터 정제 (0) | 2024.06.04 |
| Pandas 기초: 데이터 타입 확인 및 외부 CSV 데이터 로드 (0) | 2024.06.03 |
| Pandas 완전 정복: 데이터 분석의 시작과 DataFrame 생성법 (0) | 2024.06.03 |

