파이썬 주석은 코드 내에 프로그래머가 작성한 설명이나 메모를 포함하는데 사용됩니다. 주석은 코드를 이해하고 다른 개발자와 협업하는 데 도움이 되며, 코드의 기능과 목적을 명확하게 설명할 수 있습니다. 주석은 프로그램 실행 중에 무시되므로 코드 실행에 영향을 미치지 않습니다.
# window
pip install streamlit
# mac
pip3 install streamlit
# 설치 확인 및 데모 확인
streamlit hello
#실행
- 터미널에서 입력
streamlit run 파일명
import streamlit as st
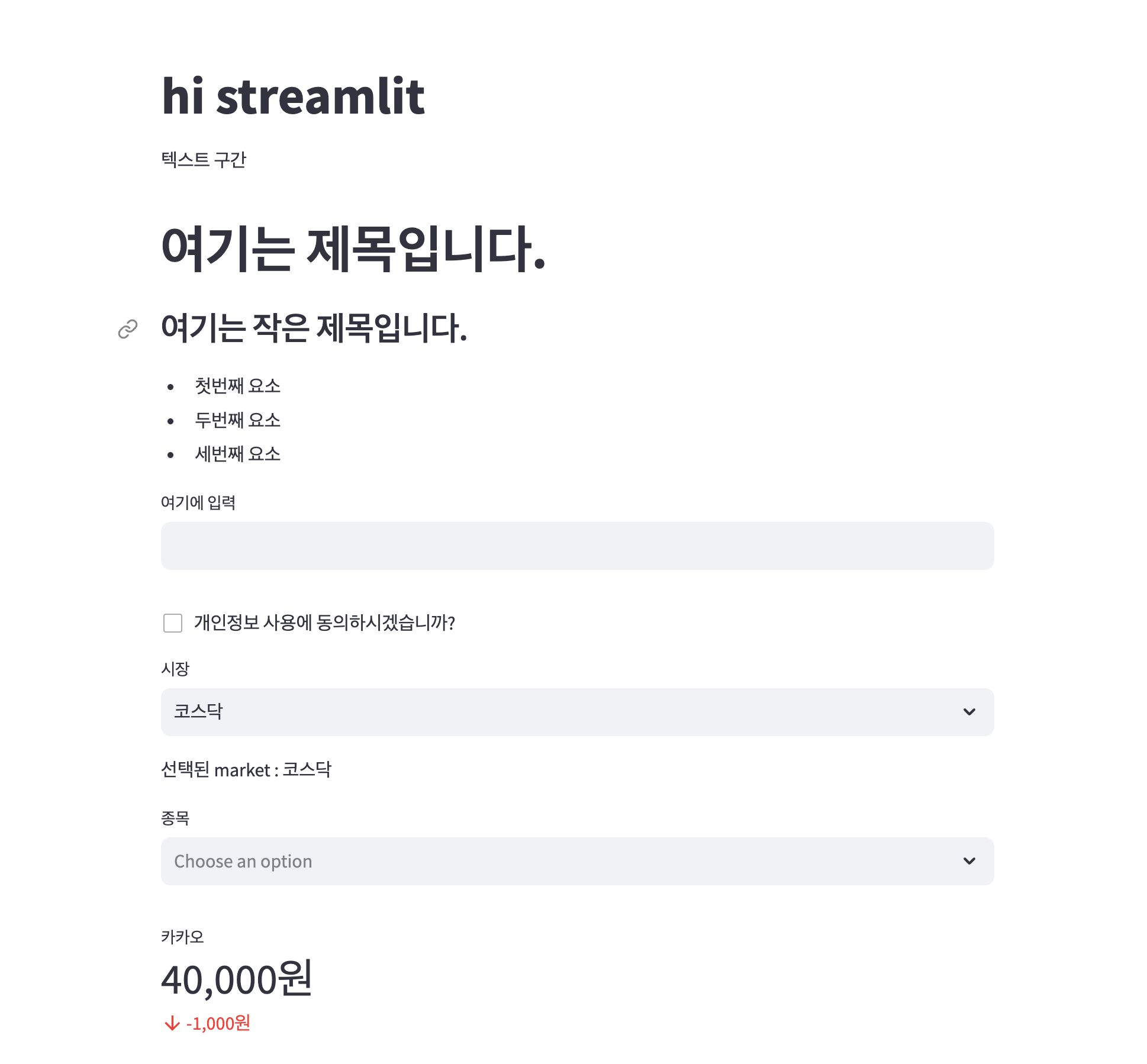
st.title('hi streamlit')
st.write('텍스트 구간')
'''
# 여기는 제목입니다.
### 여기는 작은 제목입니다.
- 첫번째 요소
- 두번째 요소
- 세번째 요소
'''
text = st.text_input('여기에 입력')
st.write(text)
selected = st.checkbox('개인정보 사용에 동의하시겠습니까?')
if selected:
st.success('동의했습니다')
market = st.selectbox('시장',('코스닥','코스피','나스닥'))
st.write(f'선택된 market : {market}')
options = st.multiselect('종목',['카카오', '네이버','삼성','엘지'])
st.write(','.join(options))
st.metric(label='카카오', value= '40,000원', delta= '-1,000원')
import chromedriver_autoinstaller
import time
from selenium import webdriver
from urllib.request import Request, urlopen
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
driver = webdriver.Chrome()
url = 'https://pixabay.com/ko/images/search/음식/'
driver.get(url)
# 이미지가 있는 주소창 xpath
image_area_xpath = '/html/body/div[1]/div[1]/div/div[2]/div[3]/div'
# 예시용 하나의 이미지 xpath
image_xpath = '/html/body/div[1]/div[1]/div/div[2]/div[3]/div/div/div[1]/div[1]/div/a/img'
import time
for _ in range(1): #스크롤을 한번만 내림
driver.execute_script('window.scrollTo(0, document.body.scrollHeight)')
# 안에 자바스크립트 문법을 쓸 수 있다. 0부터 끝까지 스크롤 이동
#time.sleep(3) #3초 쉬고 스크롤내리기
like = '/html/body/div[8]/div[1]/div/div[3]/div/div/div/div/div[2]/div/article/div/div[2]/div/div/div[2]/section[1]/span[1]/div'
driver.find_element('xpath', like).click()
# Jupyter Notebook 주요 단축키 * Enter: 일반 모드에서 편집 모드로 전환 * ESC: 편집 모드에서 일반 모드로 전환
* ▶︎일반 모드 단축키 * A: 선택된 셀 위에 새로운 셀 추가 * B: 선택된 셀 아래에 새로운 셀 추가 * X: 선택된 셀 잘라내기 * C: 선택된 셀 복사 * V: 선택된 셀 아래에 붙여넣기 * D, D: 선택된 셀 삭제 * Z: 셀 삭제 취소
* ▶︎편집 모드 단축키 * Ctrl + Z: 되돌리기 * Ctrl + Y: 되돌리기 취소 * Ctrl + A: 셀 내용 전체 선택 * Ctrl + Home: 셀 맨 위로 이동 * Ctrl + End : 셀 맨 아래로 이동 * Ctrl + D: 현재 줄 삭제 * Tab: 자동 완성 기능 사용
1. 셀레니움
셀레니움은 브라우저를 컨트롤 할 수 있도록 지원하는 라이브러리
# 셀레니움 설치
# window
!pip install selenium
# mac
!pip3 install selenium
# 크롬 드라이버 설치
# window
!pip install chromedriver_autoinstaller
# mac
!pip3 install chromedriver_autoinstaller
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome() #창 띄우기
driver.get('http://www.google.com') #구글이동
search = driver.find_element('name', 'q') # find_element: 태그에서 하나 찾기 :name에서 q만 찾기
search.send_keys('날씨') # 검색창에 날씨 입력
search.send_keys(Keys.RETURN) # 검색
데이터(data)는 정보나 사실들의 원시적이고 구조화되지 않은 형태입니다. 이것은 숫자, 문자, 이미지, 소리 등 다양한 형태로 나타날 수 있습니다. 예를 들면, 온도 측정 결과, 사진, 글, 음성 녹음 파일 등이 데이터에 해당합니다.
2. 데이터베이스
데이터베이스(database)는 관련된 데이터를 체계적으로 저장하고, 관리하고, 검색할 수 있도록 설계된 전자적 시스템입니다.
간단히 말하면, 데이터베이스는 "정보의 보관소"와 같습니다. 데이터베이스를 사용하면 크거나 작은 양의 데이터를 안전하게 저장하고 필요할 때 쉽게 찾아낼 수 있습니다.
3. 데이터베이스 관리 시스템
DBMS는 데이터베이스 관리 시스템(Database Management System)의 약자입니다. DBMS는 데이터베이스를 생성하고, 유지하고, 조작하기 위한 소프트웨어 도구의 집합입니다. 일반적으로 DBMS는 두 가지 유형으로 나뉩니다.
RDBMS (관계형 데이터베이스 관리 시스템): 데이터를 테이블 형태로 저장하며, 테이블 간의 관계를 정의할 수 있는 시스템입니다. 예로는 Oracle, MySQL, Microsoft SQL Server, PostgreSQL 등이 있습니다.
NoSQL DBMS: 관계형 모델을 사용하지 않는 데이터베이스 시스템으로, 큰 데이터 량이나 유동적인 데이터 구조를 지원하기 위해 설계되었습니다. 예로는 MongoDB, Cassandra, Redis 등이 있습니다.
4. MongoDB
MongoDB(몽고디비)는 NoSQL 데이터베이스 시스템 중 하나로, 문서 지향(document-oriented) 데이터베이스입니다. 이는 관계형 데이터베이스와는 다르게 데이터를 테이블이 아니라 JSON 스타일의 BSON(Binary JSON) 형식의 문서로 저장합니다. MongoDB는 개발자가 유연하게 데이터를 저장하고 쿼리할 수 있도록 하는 목적으로 만들어진 것이며, 대규모의 분산 데이터베이스 환경에서도 잘 동작합니다.
문서 지향 데이터베이스: MongoDB는 데이터를 BSON 형식의 문서로 저장합니다. 이 문서는 키-값 쌍(key-value pairs)으로 이루어져 있으며, 여러 종류의 데이터 유형을 포함할 수 있습니다.
스키마 없음 (Schema-less): 관계형 데이터베이스와 달리 MongoDB는 데이터베이스의 스키마를 명시적으로 정의하지 않습니다. 이는 동적인 스키마를 사용하여 데이터 모델을 유연하게 변경할 수 있도록 합니다.
유연한 데이터 모델: MongoDB는 다양한 데이터 형식을 지원하며, 중첩된 문서와 배열을 허용하여 복잡한 데이터 구조를 표현할 수 있습니다.
분산 데이터베이스: MongoDB는 여러 서버에 데이터를 분산하여 저장하고 처리할 수 있는 분산 데이터베이스 시스템을 지원합니다.
5. MongoDB Cloud
MongoDB Cloud는 MongoDB 데이터베이스를 클라우드 환경에서 제공하는 서비스입니다. MongoDB Cloud는 MongoDB, Inc.가 제공하는 공식 클라우드 서비스로서, MongoDB를 쉽게 관리하고 배포할 수 있도록 도와줍니다. 이 서비스는 데이터베이스 클러스터를 호스팅하고 관리하며, 사용자는 몽고DB 클라우드를 통해 데이터베이스를 쉽게 설정하고 확장할 수 있습니다.
- 크롤링(Crawling) : 인터넷의 데이터를 확용하기 위해 인터넷의 정보들을 수집하는 행위
- 스크레이핑(Scraping): 크롤링 + 데이터를 추출하고 가공하는 행위
2. Basig English Speaking
import requests
from bs4 import BeautifulSoup
site = 'https://basicenglishspeaking.com/daily-english-conversation-topics/'
request = requests.get(site) # 리퀘스트를 get방식으로 접속
print(request) #[200] 정상적인 접속
soup = BeautifulSoup(request.text)
# div의 딱 한부분만 가져옴
divs = soup.find('div', {'class':'thrv-columns'})
print(divs)
# div안에 있는 앵커('a')태그만 찾기
links = divs.findAll('a')
print(links)
# 리스트이기 때문에 for문으로 돌면서 텍스트만 찍기
# 앵커태그 안에 있는 텍스트만 가져오기
for link in links:
print(link.text)
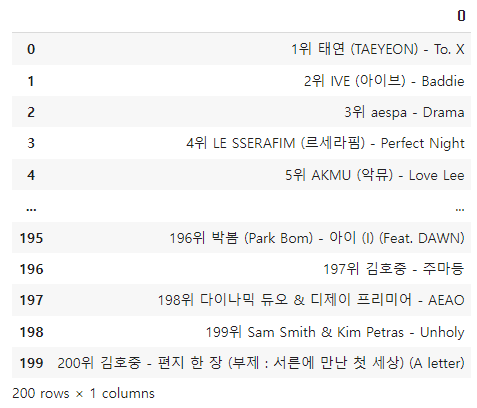
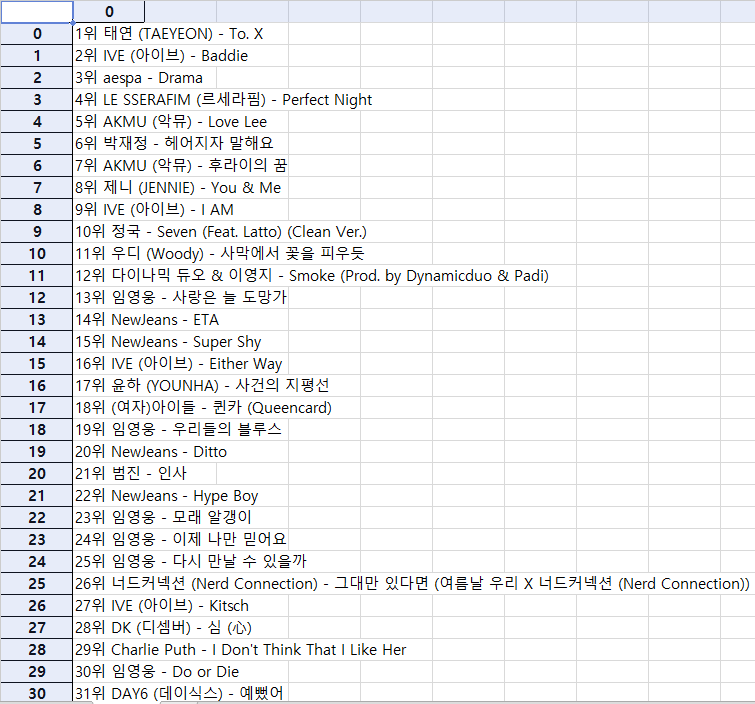
1위 ATEEZ(에이티즈) - 미친 폼 (Crazy Form) 2위 태연 (TAEYEON) - To. X 3위 LE SSERAFIM (르세라핌) - Perfect Night ... 98위 탑현 - 나에게 그대만이 99위 케이시 - 사실말야내가말야그게그러니까말이야 100위 KISS OF LIFE - Sugarcoat (NATTY Solo)
# User-Agent
# Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36
header = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7)'}
request = requests.get('https://www.melon.com/chart/index.html',headers=header)
print(request)
output
<Response [200]>
titles = soup.findAll('div',{'class':'rank01'})
#print(titles)
artists = soup.findAll('span',{'class':'checkEllipsis'})
#print(artists)
for i, (t, a) in enumerate(zip(titles, artists)):
title = t.text.strip().replace('19금\n','')#split('\n')
artist = a.text.strip()
print('{0:3d}위 {1} - {2}'.format(i+1, artist, title))
output
1위 LE SSERAFIM (르세라핌) - Perfect Night 2위 aespa - Drama 3위 IVE (아이브) - Baddie ... 98위 최유리 - 숲 99위 케이시 (Kassy) - 사실말야내가말야그게그러니까말이야 100위 BE'O (비오) - 미쳐버리겠다 (MAD)