DBMS(Database Management System) DB를 관리할 수 있는 구체적인 시스템 오라클, MySQL, MariaDB, MS-SQL, MongoDB, ...
MySQL 웹 사이트와 다양한 애플리케이션에서 사용되는 DBMS이다. 오라클은 관리 비용이 고가이지만 MySQL은 저가형 데이터베이스이다. 문법이 간결하고 쉬우며, 메모리 사용량이 현저히 낮아서 부담없이 사용 가능하다.
DBMS 소통 방식 ----------------------------------------------------- 사용자 ----------------------------------------------------- ↕ ↕ 고객 관리 응용프로그램 ↕ 주문 관리 응용프로그램 ↕ ↕ ----------------------------------------------------- DBMS -----------------------------------------------------
3) 로컬에서만 접속 가능한 계정 생성 > create user 'userid'@localhost identified by '비밀번호';
4) 원격으로도 접속 가능한 계정 생성 > create user 'userid'@'@'%' identified by '비밀번호';
5) 데이터베이스 생성 > create database [데이터베이스 이름];
6) 데이터베이스 사용 > user [데이터베이스 이름];
7) 데이터베이스 삭제 > drop database [데이터베이스 이름];
8) 사용자 비밀번호 변경 > set password for 'userid'@'%' = '신규 비밀번호';
9) 사용자 삭제 > drop user 'userid'@'%';
10) 연결 권한 > grant asll privileges on *.* to 'userid'@'%' with grant option;
11) 권한 관련 명령어 확정 > flush privileges;
SQL문(쿼리문)
- DDL (데이터 정의어)
DDL(DATA Definition Language): 데이터 정의어 - 테이블을 조작하거나 제어할 수 있는 쿼리문
자료형
- 정수
tinyint smallint mediumint int bigint
- 실수
decimal(m, d) : m자리 정수, d자리 소수점으로 표현
- 날짜
date : 1000-01-01 ~ 9999-12-31(3byte) time : -838:59:59 ~ 838:59:59(3byte) datetime : 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59(8byte)
- 문자
char(m) : 고정 길이 문자열(0~255) varchar(m) : 가변 길이 문자열(0~65535)
- Boolean
MySQL에서는 tinyint를 사용하는 것이 가장 좋다. bit(1)로 설정해도 어차피 byte 단위로 데이터를 저장하고, bool, boolean으로 설정해도 자동으로 tinyint로 변경된다. 만약 값에 의미부여를 하고 싶다면, varchar로 설정한 뒤 check 제약조건으로 이상 데이터 삽입을 막아준다. enum을 사용하면 정규화를 위반하게 되며, 설정해놓은 데이터 수정이 어렵고 다른 DBMS로 이관할 경우, MySQL에만 존재하는 enum을 모두 다른 타입으로 변경해야한다. 만약 enum을 사용하고자 한다면, 정규화 위반이 가능하도록 약속했고, 유일하고 변하지 않는 값이며, 2~10개의 값일 경우에만 사용한다.
Table
1. create: 테이블 생성
create table [테이블명] ([컬럼명] [자료형]...);
2. drop: 테이블 삭제
drop table [테이블명];
3. alter: 테이블 수정
테이블명 수정
alter table [테이블명] rename [새로운 테이블명] - 컬럼 맨 뒤에 추가 alter table [테이블명] add [컬럼명] [자료형] [제약조건]; - 컬럼 맨 앞에 추가 alter table [테이블명] add [컬럼명] [자료형] [제약조건] first; - 컬럼 지정 위치에 추가 alter table [테이블명] add [컬럼명] [자료형] [제약조건] after [기존 컬럼명]; - 컬럼 삭제 alter table [테이블명] drop [컬럼명]; - 컬럼명 변경 alter table [테이블명] change [기존컬럼명] [변경할 컬럼명] [컬럼타입]; - 컬럼 타입 변경 alter table [테이블명] modify [컬럼명] [변경할 컬럼타입]; - 제약 조건 확인 desc [데이터베이스명].[테이블명]; - 제약 조건 추가 alter table [테이블명] add constraint [제약조건 이름]; - 제약 조건 삭제 alter table [테이블명] drop constraint [제약조건 이름];
4. truncate: 테이블 내용 전체 삭제
truncate table [테이블명];
데이터 무결성
무결성 : 데이터의 정확성, 일관성, 유효성이 유지되는 것
● 정확성 : 데이터는 애매하지 않아야 한다.
● 일관성 : 각 사용자가 일관된 데이터를 볼 수 있도록 해야한다. ● 유효성 : 데이터가 실제 존재하는 데이터여야 한다.
1. 개체 무결성 모든 테이블이 PK로 선택된 컬럼을 가져야 한다.
2. 참조 무결성 두 테이블의 데이터가 항상 일관된 값을 가지도록 유지한다.
3. 도메인 무결성 컬럼의 타입, NULL값의 허용 등에 대한 사항을 정의하고 올바른 데이터가 입력되었는 지를 확인한다.
모델링(기획) : 추상적인 주제를 DB에 맞게 설계하는 것
1. 요구사항분석 회원, 주문, 상품: 3가지를 관리하고자 한다.
2. 개념적 설계(개념 모델링)
회원 주문 상품 --------------------------------- 번호 번호 번호 --------------------------------- 아이디 날짜 이름 비밀번호 회원번호 가격 이름 상품번호 재고
3. 논리적 설계(논리 모델링)
회원 주문 상품 -------------------------------------------------------- 번호PK 번호PK 번호PK -------------------------------------------------------- 아이디 U, NN 날짜 NN 이름 NN 비밀번호 NN 회원번호 FK 가격 D=0 이름 NN 상품번호 FK 재고 D=0
4. 물리적 설계(물리 모델링)
tbl_user ------------------------------------------ id: bigint primary key ------------------------------------------ user_id: varchar(255) unique not null password: varchar(255) not null name: varchar(255) not null
5. 구현
정규화
정규화
: 삽입/수정/삭제의 이상현상을 제거하기 위한 작업. 데이터의 중복을 최소화하는 데에 목적이 있다. 5차 정규화까지 있으나 3차 정규화까지만 진행한다.
1차 정규화
1차 정규화
같은 성격과 내용의 컬럼이 연속적으로 나타나거나 하나의 컬럼에 여러 값이 연속적으로 나타날 경우
상품명 와이셔츠1, 와이셔츠2, 와이셔츠3
상품명1 상품명2 상품명3 와이셔츠1 와이셔츠2 와이셔츠3
* 조회가 힘들다.
▶ 1차 정규화 진행
상품명 와이셔츠1 와이셔츠2 와이셔츠3
2차 정규화
2차 정규화
조합키(복합키)로 구성되었을 경우 조합키의 일부분에만 종속되는 속성이 있는 경우(부분 종속).
꽃 이름 색상 꽃말 과 해바라기 노란색 행운 국화 장미 빨간색 사랑 장미
"과" 속성(컬럼)은 부분종속이다.
▶ 2차 정규화 진행
꽃 이름 색상 꽃말 해바라기 노란색 행운 장미 빨간색 사랑
과 이름 과 해바라기 국화 장미 장미
3차 정규화
3차 정규화
PK가 아닌 컬럼이 다른 컬럼을 결정하는 경우. 이행함수 종속 제거.
회원번호 이름 시 구 동 우편번호 1 한라봉 경기도 남양주 화도 12345 2 홍길동 서울 강남 역삼 56466
* 우편번호로 시, 구, 동을 알 수 있다. * 중복된 데이터가 생길 가능성이 있다.
▶ 3차 정규화 진행
회원번호 이름 우편번호 1 한라봉 12345 2 홍길동 56466
우편번호 시 구 동 12345 경기도 남양주 화도 56466 서울 강남 역삼
★ 데이터베이스에서 정규화가 필요한 이유 데이터베이스를 잘못 설계하면 불필요한 데이터 중복으로 인해 공간이 낭비된다. 이런 현상을 이상(Anomaly)현상이라고 한다.
회원번호와 프로젝트코드 두 컬럼의 조합키로 설정되어 있는 테이블이고 한 사람은 하나의 부서만 가질 수 있다.
insert into [테이블명] ([컬럼명1], [컬럼명2], ...) values([값1], [값2], ...);
2) 모든 값을 전부 작성한다.
insert into [테이블명] values([값1], [값2], ...);
3. update
update [테이블명] set [기존 컬럼명1] = [새로운 값1], [기존 컬럼명2] = [새로운 값2], ... where [조건식];
4. delete
delete from [테이블명] where [조건식];
조건식
>, <
초과, 미만
>=, <=
이상, 이하
=
같다
<>, !=, ^=
같지 않다
AND
둘 다 참이면 참
OR
둘 다 아니어도 참
join
: 여러 테이블에 흩어져 있는 정보 중 사용자가 필요한 정보만 가져와서 가상의 테이블처럼 만들고 결과를 보여주는 것. 정규화를 통해 조회 테이블이 너무 많이 쪼개져 있으면, 작업이 불편하기 떄문에 조회의 성능을 향상시키고자 join을 사용한다.
- 내부 조인(inner join)
from [테이블명] inner join [테이블명] on 조건식 inner join [테이블명] on 조건식 inner join [테이블명] on 조건식 ...
- 등가 조인 : on절에 등호가 있을 때, 서로 관계를 맺고 있는 테이블끼리 JOIN할 때 주로 사용된다.
- 비등가 조인 : on절에 등호가 없을 때, 서로 관계를 맺지 않고 있는 테이블끼리 JOIN할 때 주로 사용된다.
- 외부 조인(outer join)
: 조건에 일치하지 않아도 원하는 정보까지 합쳐서 조회
- left outer join
선행 테이블의 모든 정보를 가져오고 싶을 때 사용한다.
- right outer join
후행 테이블의 모든 정보를 가져오고 싶을 때 사용한다.
옵티마이저(Optimizer)
SQL을 가장 빠르고 효율적으로 수행할 최적의 처리경로(최적비용)을 생성해주는 DBMS 내부의 핵심 엔진 사용자가 쿼리문(SQL)으로 결과를 요청하면, 이를 생성하는 데 필요한 처리경로는 DBMS에 내장된 옵티마이저가 자동으로 생성한다. 옵티마이저가 생성한 SQL 처리경로를 실행 계획(Execution Plan)이라고 한다. COST: 예상 수행 시간, 쿼리를 수행하는 데 소요되는 일량 또는 시간 CARDINALiTY: 실행 결과의 건수
옵티마이저의 SQL 최적화 과정 사용자가 작성한 쿼리를 수행하기 위해, 실행 계획을 찾는다. 데이터 딕셔너리에 미리 수집해 놓은 오브젝트 통계 및 시스템 통계 정보를 이용해서 각 실행계획의 예상 비용을 산정한다. 각 실행계획을 비교해서 최저 비용을 갖는 하나를 선택하여 실행한다.
옵티마이저의 종류
1. 규칙기반 옵티마이저(RBO) 미리 정해진 규칙에 따라 실행
2. 비용기반 옵티마이저(CBO) 비용이 가장 낮은 실행계획을 선택
SQL문(쿼리문)
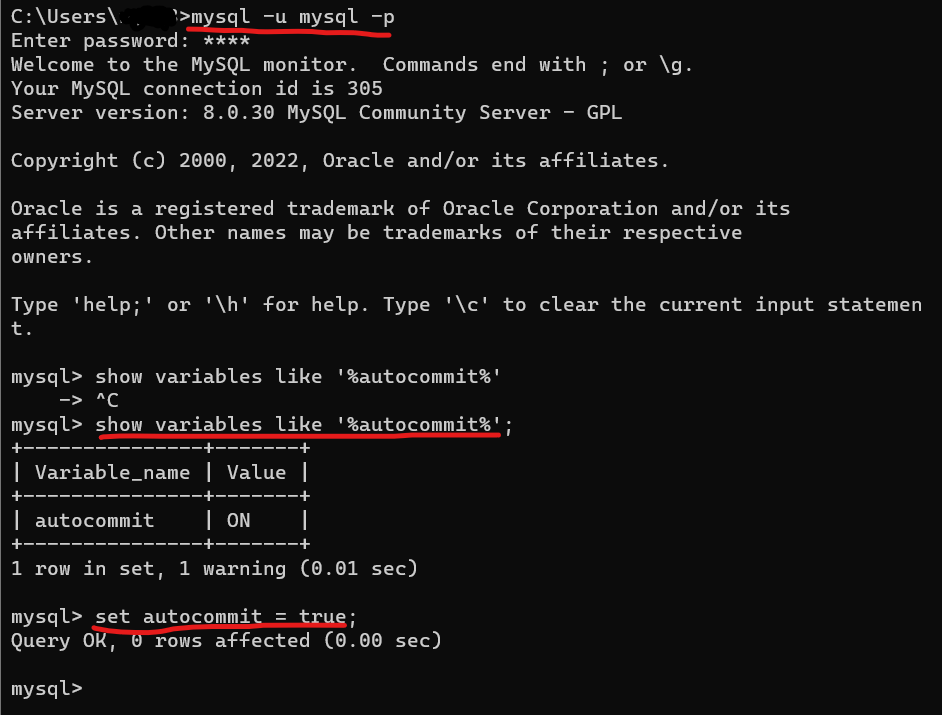
- TCL(Transaction Control Language) : 트랙잭션 제어어
트랜잭션 : 하나의 작업(서비스)에 필요한 쿼리를 묶은 단위
commit : 모든 작업을 확정하는 명령어
rollback : 이전 커밋 시점으로 이동
> show variables like '%autocommit%';
> set autocommit = true; > set autocommit = false;
VIEW
기존의 테이블은 그대로 놔둔 채 필요한 컬럼들 새로운 컬럼을 만든 가상 테이블. 실제 데이터가 저장되는 것은 아니지만 VIEW를 통해서 충분히 데이터를 관리할 수 있다.
- 독립성: 다른 곳에서 접근하지 못하도록 하는 성질 - 편리성: 긴 쿼리문을 짧게 만드는 성질 - 보안성: 기존의 쿼리문이 모이지 않는다.
데이터(data)는 정보나 사실들의 원시적이고 구조화되지 않은 형태입니다. 이것은 숫자, 문자, 이미지, 소리 등 다양한 형태로 나타날 수 있습니다. 예를 들면, 온도 측정 결과, 사진, 글, 음성 녹음 파일 등이 데이터에 해당합니다.
2. 데이터베이스
데이터베이스(database)는 관련된 데이터를 체계적으로 저장하고, 관리하고, 검색할 수 있도록 설계된 전자적 시스템입니다.
간단히 말하면, 데이터베이스는 "정보의 보관소"와 같습니다. 데이터베이스를 사용하면 크거나 작은 양의 데이터를 안전하게 저장하고 필요할 때 쉽게 찾아낼 수 있습니다.
3. 데이터베이스 관리 시스템
DBMS는 데이터베이스 관리 시스템(Database Management System)의 약자입니다. DBMS는 데이터베이스를 생성하고, 유지하고, 조작하기 위한 소프트웨어 도구의 집합입니다. 일반적으로 DBMS는 두 가지 유형으로 나뉩니다.
RDBMS (관계형 데이터베이스 관리 시스템): 데이터를 테이블 형태로 저장하며, 테이블 간의 관계를 정의할 수 있는 시스템입니다. 예로는 Oracle, MySQL, Microsoft SQL Server, PostgreSQL 등이 있습니다.
NoSQL DBMS: 관계형 모델을 사용하지 않는 데이터베이스 시스템으로, 큰 데이터 량이나 유동적인 데이터 구조를 지원하기 위해 설계되었습니다. 예로는 MongoDB, Cassandra, Redis 등이 있습니다.
4. MongoDB
MongoDB(몽고디비)는 NoSQL 데이터베이스 시스템 중 하나로, 문서 지향(document-oriented) 데이터베이스입니다. 이는 관계형 데이터베이스와는 다르게 데이터를 테이블이 아니라 JSON 스타일의 BSON(Binary JSON) 형식의 문서로 저장합니다. MongoDB는 개발자가 유연하게 데이터를 저장하고 쿼리할 수 있도록 하는 목적으로 만들어진 것이며, 대규모의 분산 데이터베이스 환경에서도 잘 동작합니다.
문서 지향 데이터베이스: MongoDB는 데이터를 BSON 형식의 문서로 저장합니다. 이 문서는 키-값 쌍(key-value pairs)으로 이루어져 있으며, 여러 종류의 데이터 유형을 포함할 수 있습니다.
스키마 없음 (Schema-less): 관계형 데이터베이스와 달리 MongoDB는 데이터베이스의 스키마를 명시적으로 정의하지 않습니다. 이는 동적인 스키마를 사용하여 데이터 모델을 유연하게 변경할 수 있도록 합니다.
유연한 데이터 모델: MongoDB는 다양한 데이터 형식을 지원하며, 중첩된 문서와 배열을 허용하여 복잡한 데이터 구조를 표현할 수 있습니다.
분산 데이터베이스: MongoDB는 여러 서버에 데이터를 분산하여 저장하고 처리할 수 있는 분산 데이터베이스 시스템을 지원합니다.
5. MongoDB Cloud
MongoDB Cloud는 MongoDB 데이터베이스를 클라우드 환경에서 제공하는 서비스입니다. MongoDB Cloud는 MongoDB, Inc.가 제공하는 공식 클라우드 서비스로서, MongoDB를 쉽게 관리하고 배포할 수 있도록 도와줍니다. 이 서비스는 데이터베이스 클러스터를 호스팅하고 관리하며, 사용자는 몽고DB 클라우드를 통해 데이터베이스를 쉽게 설정하고 확장할 수 있습니다.