

1번
F-검정 통계량 :

F = (큰 분산) / (작은 분산)
- df₁(분자 자유도) = 더 큰 분산 쪽의 자유도
- df₂(분모 자유도) = 더 작은 분산 쪽의 자유도
- 항상 “분자의 자유도가 분모의 자유도보다 크도록” 맞추는 것
2. 합동분산(Sp²) 추정량
합동분산에 반드시 np.var(…, ddof=1) 값(=S₁², S₂²)을 넣으셔야 합니다!
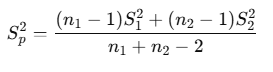
- n1, n2 : 집단 표본 크기
- S₁², S₂² : 각 집단의 표본분산(ddof=1)
Sp2 = ((n1-1)varA + (n2-1)varB) / n1+n2-2
3번. 합동분산 t검정
import pandas as pd
import numpy as np
df = pd.read_csv("data/bcc.csv")
import pandas as pd
import numpy as np
from scipy import stats
# 데이터프레임 생성(파일에서 읽는 경우는 주석 처리)
# df = pd.read_csv("data/bcc.csv")
# 데이터 직접 복사한 경우 아래처럼 사용 (이미 df에 데이터 있음)
# 1. 그룹 분리
class1 = df[df['Classification']==1]['Resistin']
class2 = df[df['Classification']==2]['Resistin']
# 2. 로그변환
log1 = np.log(class1)
log2 = np.log(class2)
n1, n2 = len(log1), len(log2)
var1 = np.var(log1, ddof=1)
var2 = np.var(log2, ddof=1)
# (1) F-검정: 더 큰 분산/더 작은 분산
if var1 > var2:
F = var1 / var2
df1 = n1 - 1
df2 = n2 - 1
else:
F = var2 / var1
df1 = n2 - 1
df2 = n1 - 1
print(round(F, 3)) # ① F-값
# (2) 합동분산
Sp2 = ((n1-1)*var1 + (n2-1)*var2) / (n1+n2-2)
print(round(Sp2, 3)) # ② 합동분산
# (3) 합동분산 t-검정
mean1 = np.mean(log1)
mean2 = np.mean(log2)
t_num = mean1 - mean2
t_den = np.sqrt(Sp2 * (1/n1 + 1/n2))
t_stat = t_num / t_den
dfree = n1 + n2 - 2
p_val = 2 * (1 - stats.t.cdf(abs(t_stat), df=dfree))
print(round(t_stat, 3)) # ③-1 t-값
print(round(p_val, 3)) # ③-2 p-값
# + (3) 합동분산 t-검정 함수 이용방법
t_stat2, p_val2 = stats.ttest_ind(log1, log2, equal_var=True)
print(round(t_stat2, 3), round(p_val2, 3))'빅데이터 분석기사 > 정리' 카테고리의 다른 글
| import warnings [python 경고메시지 무시] (0) | 2025.06.12 |
|---|---|
| numpy의 표준편차와 pandas의 표준편차 차이 (0) | 2025.06.12 |
| 빅데이터분석기사 실기체험 2번 (0) | 2025.06.07 |
| 빅데이터분석기사 실기체험 1번 (0) | 2025.06.06 |
| 시계열 데이터 함수 정리 (0) | 2025.06.02 |