

1. 크롤링과 스크레이핑
- 크롤링(Crawling) : 인터넷의 데이터를 확용하기 위해 인터넷의 정보들을 수집하는 행위
- 스크레이핑(Scraping): 크롤링 + 데이터를 추출하고 가공하는 행위
2. Basig English Speaking
import requests
from bs4 import BeautifulSoup
site = 'https://basicenglishspeaking.com/daily-english-conversation-topics/'
request = requests.get(site) # 리퀘스트를 get방식으로 접속
print(request) #[200] 정상적인 접속output
<Response [200]> #정상적인 접속
print(request.text) #가져온 html 확인soup = BeautifulSoup(request.text)
# div의 딱 한부분만 가져옴
divs = soup.find('div', {'class':'thrv-columns'})
print(divs)
# div안에 있는 앵커('a')태그만 찾기
links = divs.findAll('a')
print(links)
# 리스트이기 때문에 for문으로 돌면서 텍스트만 찍기
# 앵커태그 안에 있는 텍스트만 가져오기
for link in links:
print(link.text)output
Family
Restaurant
Books
...
Handcraft Items
Plastic Surgery
Success
subject = []
for link in links: # (links)에서 앵커태그를 하나씩 링크(link)로 뽑아 빈 리스트에 텍스트가 하나씩 들어감
subject.append(link.text)len(subject)output
75
print('총', len(subject), '개의 주제를 찾았습니다.')
for i in range(len(subject)):
print('{0:2d}, {1:s}'.format(i+1, subject[i]))
output
총 75 개의 주제를 찾았습니다.
1. Family
2. Restaurant
3. Books
...
73. Handcraft Items
74. Plastic Surgery
75. Success
3. 다음 뉴스기사
# 제목을 뽑아보는 크롤링
크롤링할 기사
#https://v.daum.net/v/20231124152902275
def daum_news_title(news_id):
url = 'https://v.daum.net/v/{}'.format(news_id)
request = requests.get(url)
soup = BeautifulSoup(request.text)
title = soup.find('h3', {'class':'tit_view'}) # class안 tit_view 찾기
if title:
return title.text.strip()
return '제목없음'
daum_news_title('20231124152902275')output
' 김유정 "이상이와 1년간 매일같이 보고 있어, 어색할까 걱정" (\'마이 데몬\') '
daum_news_title('20231124144808698')output
'한효주, 美에미상 빛냈다..'큰칼' 잊게 만든 우아美+유창한 영어 [종합]'
4. 벅스 뮤직차트
벅스차트
# https://music.bugs.co.kr/chart
request = requests.get('https://music.bugs.co.kr/chart')
soup = BeautifulSoup(request.text)
titles = soup.findAll('p', {'class':'title'}) # findAll : 선택한 항목의 모든요소 찾기
#print(titles)
artists = soup.findAll('p',{'class':'artist'})
#print(artists)
for i, (t, a) in enumerate(zip(titles, artists)):
title = t.text.strip().replace('[19금]\n', '') # replace -> 19금 -> ''변경
artist = a.text.strip().split('\n')[0] # 스플릿으로 문자열을 나눈 후 공백을 삭제후 첫번째 요소만 출력
print('{0:3d}위 {1} - {2}'.format(i+1, artist, title))
# enumerate : 반복문을 사용할 때 인덱스와 값을 함께 가져오기 위해 사용되는 내장 함수
# zip 함수 : zip() 함수는 파이썬에서 여러 개의 반복 가능한(iterable) 객체를 병렬적으로 묶어주는 내장 함수
output
1위 ATEEZ(에이티즈) - 미친 폼 (Crazy Form)
2위 태연 (TAEYEON) - To. X
3위 LE SSERAFIM (르세라핌) - Perfect Night
...
98위 탑현 - 나에게 그대만이
99위 케이시 - 사실말야내가말야그게그러니까말이야
100위 KISS OF LIFE - Sugarcoat (NATTY Solo)
5. 멜론차트
- robots.txt : 웹 사이트에 크롤러같은 로봇들의 접근을 제어하기 위한 규약 (권고안이라 꼭 지킬 의무는 없음) (https://www.melon.com/robots.txt)
멜론차트
#https://www.melon.com/chart/index.htm
request = requests.get('https://www.melon.com/chart/index.html')
print(request)| output |
| <Response [406]> #406번은 정보를 가져오지 못한 것 |
titles = soup.findAll('div class',{'class' : 'title'})
print(titles)| ouput |
| [] |
이럴땐 User-Agent가 필요
User-Agent
# User-Agent
# Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36
header = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7)'}
request = requests.get('https://www.melon.com/chart/index.html',headers=header)
print(request)| output |
| <Response [200]> |
titles = soup.findAll('div',{'class':'rank01'})
#print(titles)
artists = soup.findAll('span',{'class':'checkEllipsis'})
#print(artists)
for i, (t, a) in enumerate(zip(titles, artists)):
title = t.text.strip().replace('19금\n','')#split('\n')
artist = a.text.strip()
print('{0:3d}위 {1} - {2}'.format(i+1, artist, title))| output |
| 1위 LE SSERAFIM (르세라핌) - Perfect Night 2위 aespa - Drama 3위 IVE (아이브) - Baddie ... 98위 최유리 - 숲 99위 케이시 (Kassy) - 사실말야내가말야그게그러니까말이야 100위 BE'O (비오) - 미쳐버리겠다 (MAD) |
6. 네이버증권
|
# 이름, 가격, 종목코드, 거래량
# 그린리소스, (가격 : 52,300, 종목코드 : 402490, 거래량 : 34,192,513))
# {'name':'그린리소스, 'price':52300, code: '402490', 'volume': 34192513}
|
request = requests.get('https://finance.naver.com/item/main.naver?code=402490')
soup = BeautifulSoup(request.text)
# 이름
div_totalinfo = soup.find('div', {'class':'new_totalinfo'})
name = div_totalinfo.find('h2').text
# 가격
div_today = div_totalinfo.find('div', {'class':'today'})
em = div_today.find('em')
price = div_today.find('span',{'class':'blind'}).text
# 종목코드
div_code = div_totalinfo.find('div', {'class':'description'})
code = div_code.find('span',{'class':'code'}).text
# 거래량
table_no_info = soup.find('table',{'class','no_info'})
tds = table_no_info.findAll('td')
volume = tds[2].find('span',{'class':'blind'}).text
# 딕셔너리
dic = {'name': name, 'code':code, 'price':price, 'volume':volume}
print(dic)
네이버증권 종목코드로 정보추출하는 함수
def naver_finance(code):
# 코드
site = f'https://finance.naver.com/item/main.naver?code={code}'
request = requests.get(site)
soup = BeautifulSoup(request.text)
# 이름
div_totalinfo = soup.find('div', {'class':'new_totalinfo'})
name = div_totalinfo.find('h2').text
# 가격
div_today = div_totalinfo.find('div', {'class':'today'})
em = div_today.find('em')
price = em.find('span', {'class':'blind'}).text
# 거래량
table_no_info = soup.find('table', {'class':'no_info'})
tds = table_no_info.findAll('td')
volume = tds[2].find('span', {'class':'blind'}).text
dic = {'name':name, 'code':code, 'price':price, 'volume':volume}
return dic
naver_finance('252670')| output |
| {'name': 'KODEX 200선물인버스2X', 'code': '252670', 'price': '2,580', volume': '79,577,748'} |
naver_finance('032790')| output |
| {'name': '엠젠솔루션', 'code': '032790', 'price': '1,928', 'volume': '692,851'} |
codes = ['017040', '007980', '352090', '402490', '032790']
data = []
for code in codes:
dic = naver_finance(code)
data.append(dic)
print(data)| output |
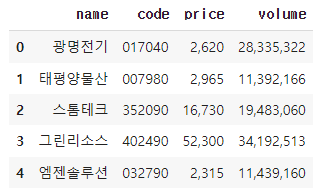
| [{'name': '광명전기', 'code': '017040', 'price': '2,430', 'volume': '757,418'}, {'name': '태평양물산', 'code': '007980', 'price': '2,985', 'volume': '3,630,259'}, {'name': '스톰테크', 'code': '352090', 'price': '12,510', 'volume': '803,272'}, {'name': '그린리소스', 'code': '402490', 'price': '34,750', 'volume': '1,371,371'}, {'name': '엠젠솔루션', 'code': '032790', 'price': '1,928', 'volume': '692,851'}] |
# 데이터프레임 생성
# pandas: 데이터를 2차원으로 바꿔주는 기능
import pandas as pd
df = pd.DataFrame(data)
df| output |
 |
# 자료를 엑셀로 변환
df.to_excel('naver_finace.xlsx') # 자료 -> 엑셀 변환
|
# 지니뮤직
# https://www.genie.co.kr/ # ...
# import time을 이용
# time.sleep(3)
# 지니차트 1 ~ 200위까지 크롤링해서 엑셀로 만들기
|
import time
import requests
import pandas as pd
from bs4 import BeautifulSoup
# 상위 200위까지 출력
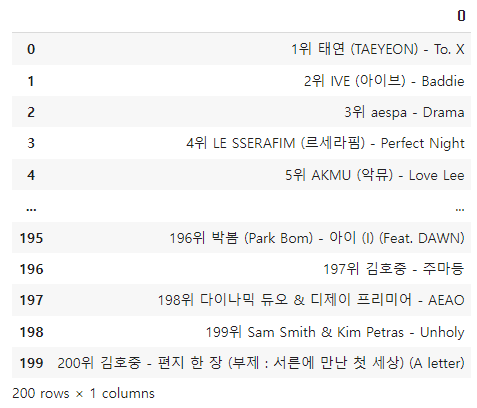
data = []
for j in range(1, 5): # 페이지는 1에서 4까지
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'}
request = requests.get(f'https://www.genie.co.kr/chart/top200?ditc=D&ymd=20231124&hh=21&rtm=Y&pg={j}', headers=header)
soup = BeautifulSoup(request.text)
table = soup.find('table', {'class': 'list-wrap'})
titles = table.findAll('a', {'class': 'title ellipsis'})
artist = table.findAll('a', {'class': 'artist ellipsis'})
number = soup.findAll('td', {'class': 'number'})
for i, (n, t, a) in enumerate(zip(number, titles, artist)):
numbers = n.text.strip().split('\n')[0]
titles = t.text.strip().replace('19금', '').lstrip() # 19금 아이콘 제거
artists = a.text.strip()
dic =('{0}위 {1} - {2}'.format(numbers, artists, titles))
data.append(dic)
time.sleep(2)
df = pd.DataFrame(data)
df
| output |
 |
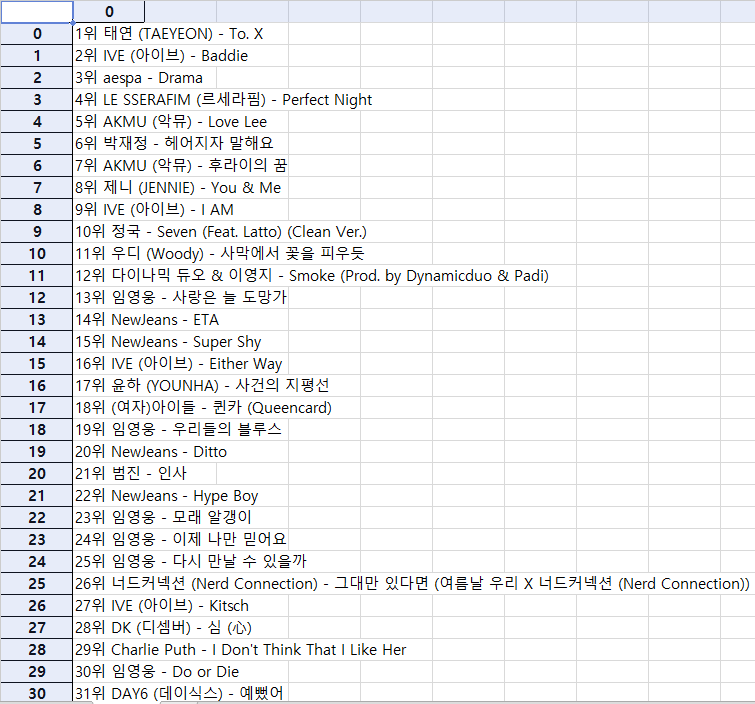
df.to_excel('지니.xlsx')| 지니.xlsx 파일 |
 |